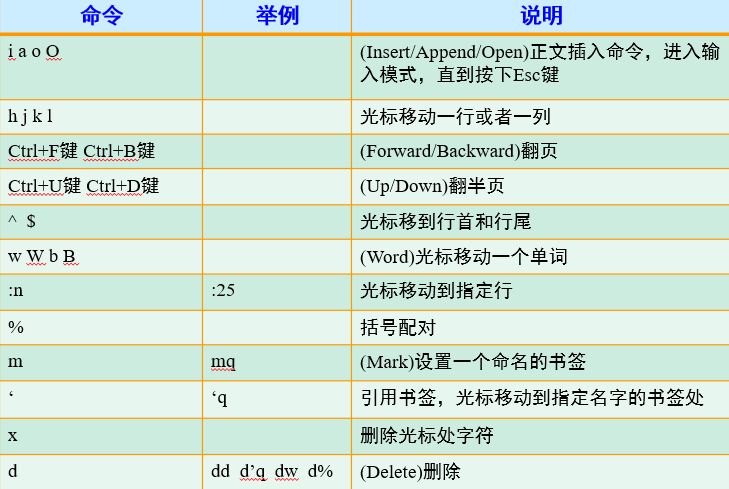
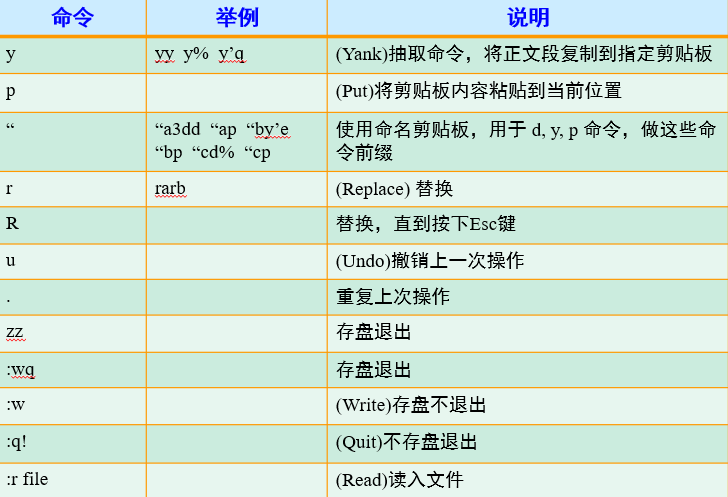
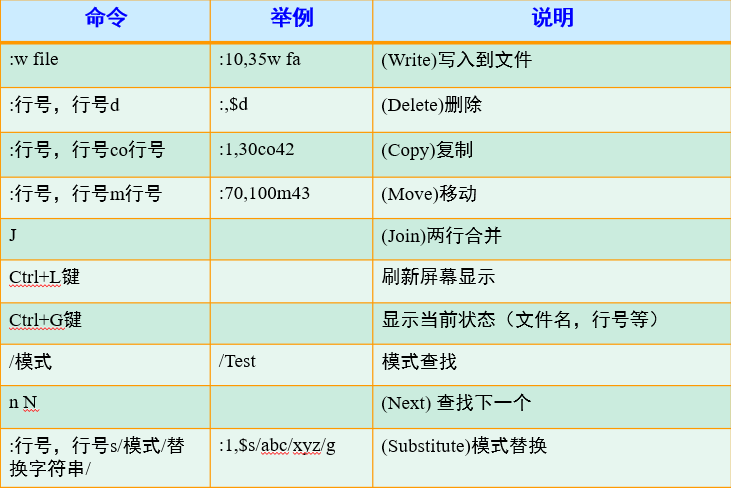
Linux概述
开始使用Linux
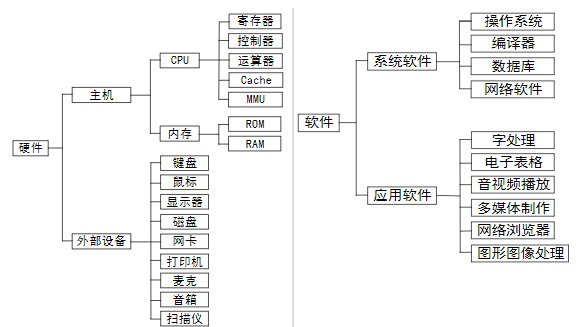
计算机系统的组成
操作系统的发展
- 手工操作
- 单道批处理操作系统
- 多道批处理系统
- 分时系统
多道程序需要的硬件支持
中断
- CPU收到外部信号后,停止原来工作,转去处理该事件,完毕后回到原来断点继续工作
通道:专用的I/O处理器
- 控制I/O设备与内存间的数据传输,启动后独立于CPU运行,实现CPU与I/O的并行
- 多道程序的加载
- 程序采用虚拟地址,以保证多道同时运行的程序可以在内存中的重定位(虚实地址转换)
- 内存保护
- 内核的编程接口:应用程序调用操作系统提供的功能
- 用户态程序无法直接使用核心态程序,一般系统调用采用软件中断(trap)方式,CPU进入核心态执行
- 可以认为操作系统就是所有中断服务程序的集合,包括硬件中断和软件中断
系统调用和普通函数调用的区别
- 在UNIX系统中,都以C语言函数方式给出
- 实现普通函数调用的代码在CPU用户态下运行,包含在可执行程序内,使用CALL指令,利用堆栈实现,函数调用结束后返回调用处的下一条语句(库函数与自定义函数)
- 实现系统调用功能的代码在内核中,用户程序通过使用INT指令产生软中断进入内核执行,使用进程的核心态堆栈,执行完毕后中断返回
系统命令
- 操作系统自带的命令也是利用系统调用设计的应用程序,与普通的应用程序具有相同地位
应用软件和设备驱动程序开发
应用软件开发
- 直接使用系统调用(如:Unix)
- 将系统调用封装为函数库API(如Win32)
- 使用框架,如MFC
- 应用软件运行时CPU处于用户态
设备驱动程序开发DDK
- 操作系统中对设备分类,例如:网卡,磁盘,显示器,打印机,声卡,音频输入,视频输入
- 每类设备设计一种抽象的接口,包括多个函数
- 设备驱动程序操纵硬件,处理中断,提供这类设备接口规定的一组函数。函数的调用时机由操作系统决定
- 设备驱动程序工作在CPU特权级,驱动程序的BUG可能会导致整个系统崩溃
- 一般设备驱动程序通过动态链接的方式链接入内核
字符终端
UNIX/Linux是多用户系统
- 主机连接多台字符终端
- 字符终端作为交互式输入输出设备
终端的构成
- 键盘
- 显示器
- RS232串行通信接口
字符终端的历史
- 英文打字机 typewriter
- 电传打字机 teletypewriter,简写tty
- 字符终端,仍称做tty设备
主机与终端的链接
- 主机中的串口卡(硬件)引出多个RS232串口
- 每个RS232接口通过电缆(3芯或更多芯)连接一台终端
- RS232电缆的长度限制
- 不同的硬件需要不同的驱动程序
- 与行律模块的接口:上行和下行字符流
行律的作用
- 一行内字符的缓冲、回显与编辑,直到按下回车键
- 数据加工,如:将\n(换行)转化为\r\n(回车换行)
- 将Ctrl-C字符转化为中止进程的信号
终端转义序列
转义字符
- Esc:ASCII码1B(十进制27,八进制033)
主机发往终端方向数据中的转义序列的功能
- 控制光标位置、字符颜色、字符大小等等
- 选择终端的字符集
- 控制终端上的打印机、刷卡机、磁条器、密码键盘
举例
- Esc[2J 由主机发送到终端的四字节序列:1B 5B 32 4A 功能:清除屏幕
- Esc[8A 四字节序列,光标上移8行
- Esc[16;8H 七字节序列,光标移到16行8列
- Esc[1;31m 七字节序列,红色字符;程序中用字符串格式”\033[1;31m”
主机和终端之间的流量控制
必要性
- 终端的显示速度跟不上主机的发送速度
- 主机送来数据终端需要打印出来,但打印速度慢
- 主机送来的显示内容,需暂停显示,仔细分析
- 需要一种机制控制主机方向来的数据流量
两种流控方式
- 硬件方式:RS232接口的CTS信号线
- 软件方式:利用流控字符Xon(要求主机继续发送,Ctrl-Q)和Xoff(要求主机暂停发送数据,Ctrl-S)
仿真终端和虚拟终端
仿真终端
- PC机串口,运行终端仿真软件来仿真终端。
例如:DOS操作系统下的CrossTalk,Windows中的”超级终端“虚拟终端
- UNIX主机与PC机通过网络相连,客户端运行telnet,服务器端运行telnetd,称为UNIX的一个基于TCP通信的虚拟终端
- 安全终端:在TCP连接上加密和压缩数据,如:Windows客户端软件SecureCRT
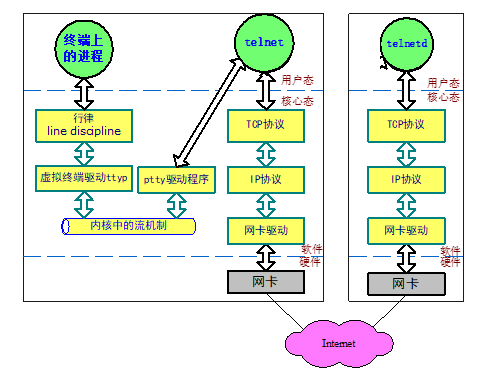
系统状态查看工具
开始使用Linux
用户登录和联机手册的查阅
useradd
useradd tt
root用户(超级用户)不受权限的制约,可随意修改和删除文件,使用useradd命令创建新用户,用户信息存放在/etc/passwd文件中,包括用户名和用户ID,以及Home目录,登录shell(一般为bash,也可以选其他shell,其他系统程序,甚至自设计的程序)
man
man name
man命令取自manual(说明手册)的前三个字母,用于查阅联机手册
手册页的内容:
- 列出基本功能和语法
- 对于C语言的函数调用,列出头文件和链接函数库
- 功能说明
- SEE ALSO:有关的其他项目的名字和章节号
man section name # 在某章中查询相关条目
常用章节编号:1命令 2系统调用 3库函数 5配置文件
man -k regexp # 列出关键字与正则表达式regexp匹配的条目
时间、计算器和口令维护
date
date
Wed Nov 7 21:09:16 CST 2018>
date用于读取系统日期和时间
date “+%Y-%m-%d %H:%M:%S Day %j”
2018-11-07 21:09:54 Day 311
- 311指的是今年第311天
- 格式控制字符串:第一个字符必须为+号,%m代表月,%M代表分钟
- %s秒坐标(从UTC1970开始),常用于计算时间间隔
ntpdate 0.pool.ntp.org # 通过NTP协议校对系统时间,必须root用户
ntpdate -q 0.pool.ntp.org # 查询时间,普通用户也可以
cal
cal # 打印当前月份的日历
cal year # 打印指定年的日历
cal month year # 打印指定年月的日历
cal 12 # 打印公元12年的日历
bc
bc # 缺省精度为小数点后0位
bc -l # 缺省精度为小数点后20位
可以通过scale自行决定精度(小数点位数)
scale=10000
passwd
passwd # 更改自己的口令
passwd liu # root用户强迫更改liu的口令
普通用户
- 使用passwd命令更改自己的口令,更改前要先验证原来的口令
超级用户root - 修改口令之前不验证旧的口令
- 可修改自己的口令,无法读取其他用户的口令,但可以强迫设置其他用户口令(passed liu)

了解系统状态
who
who # 显示当前登录系统的用户
root tty7 2014-05-13 12:12 (:0)
root pts/0 2014-05-14 17:09 (:0.0)
root pts/1 2014-05-14 18:51 (192.168.1.17)
root pts/2 2014-05-14 19:48 (192.168.1.17)
- 第一列:用户名,第二列:终端设备的设备文件名
- 设备在文件系统中有一个文件名(同普通磁盘文件不同的是文件类型属于特殊文件),设备文件一般放于目录/dev下
tty # 打印出当前终端的设备文件名
who am i # 登录shell时的用户名
whoami # 当前系统的有效用户
uptime
uptime
05:52:21 up 412 days, 4:15, 5 users, load average: 0.55, 0.73, 0.43
- 系统自启动后到现在的运行时间
- 当前登录系统的用户数
- 近期1分钟,5分钟,15分钟内系统CPU的负载
top
top # 列出资源占用排名靠前的进程
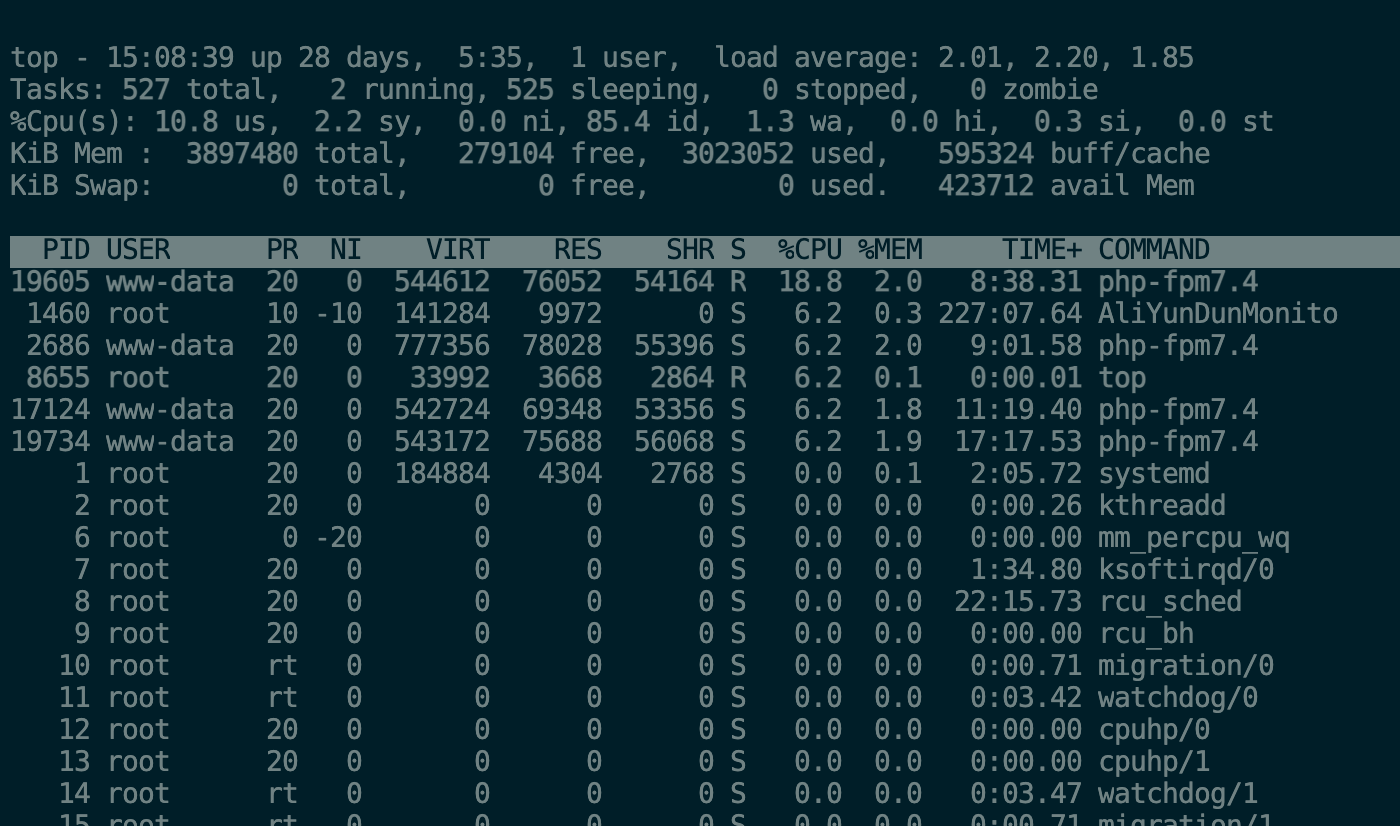
- VIRT:进程逻辑地址空间大小
- RES:占用物理内存数
- SHR:与其他进程共享的内存数
- %CPU:占用CPU百分比
- %MEM:占用内存百分比
- TIME+:占用的CPU时间
ps(process status)
ps # 只列出在当前终端上启动的进程
ps -e # 列出系统所有的进程
ps -f # 以full格式列出每一个进程
ps -l # 以long格式列出每一个进程
- UID:用户ID
- PID:进程ID
- PPID:父进程的PID
- C:CPU占用指数
- STIME:启动时间
- SZ:进程逻辑内存大小(持续增加:内存泄漏)
- TTY:终端的名字
- COMMAND:命令名
- WCHAN:进程在内核的何处睡眠(wait channel)
- TIME:累计执行时间
- PRI:优先级
- S:状态,S(sleep),R(run),Z(zombie)
free
free # 了解内存使用情况
total used free shared buffers cached
Mem: 254772 184568 70204 0 5692 89892
Swap: 524280 65116 459164
vmstat
vmstat # 了解系统负载
vmstat 2 1 # 每2秒采集一次服务器状态,只采集1次

telnet/ssh
telnet 202.172.122.135
telnet cdc.xynet.edu.cn
这两个指令用于远程登录,使用telnet/ssh时对方必须实现开启了TELNET/SSH服务,两者的区别主要在于安全性,SSH提供了加密和更强大的身份验证选项。
ftp
ftp 202.172.122.135
ftp cdc.xynet.edu.cn
用于文件传送,对方必须实现开启了FTP服务。
ftp常用命令:dir、get、put、cd、lcd(local cd)、mkdir、rmdir、delete、rename、ascii(设置ASCII码方式传送文件)、binary(设置二进制方式传送文件)、bye(退出ftp)
Window和Unix文本文件结构的不同
- 文本文件行的行尾不同
- UNIX:行尾处仅存换行字符
- Windows:行尾处存回车和换行两个字符
- 例:文件mini.txt中,第一行为ab,第二行为xyz
- UNIX:文件大小为7字节,61 62 0a 78 79 7a 0a
- Windows:文件大小为9字节,61 62 0d 78 79 7a 0d 0a
VNC(Virtual Network Computing)
VNC是一种远程桌面协议,允许用户远程访问和控制另一台计算机的桌面。它使用户能够在远程计算机上看到和操作图形用户界面(GUI),就像他们坐在该计算机前一样。
Samba
Samba是一个开源的软件套件,用于实现Windows网络协议(如SMB/CIFS)在Linux和其他UNIX系统上的兼容性,以实现文件和打印共享。
文本文件的处理
读取文件内容
more/less
more shudu.c # 指定一个文件
more *.[ch] # 指定多个文件
ls -l | more # 指定0个文件(效果同ls -l)
less shudu.c
more命令:空格(翻页)、回车(上滚一行)、q(quit)、/pattern(搜索指定模式字符串)、h(help)、Ctrl-L(屏幕刷新)
less命令:回退浏览的功能更强,可直接使键盘的上下箭头键,或者j,k,类似vi的光标定位键,以及PgUp,PgDn,Home,End键
cat/od
cat tryl.c
cat -n shudu.c # 显示行号
cat >try # 从stdin输入到文件try,直到ctrl-d
cat tryl.c try2.c try.h > trysrcod -t x1 x.dat # 以十六进制打印文件x.dat各字节
head/tail
head ab.c # 显示文件的头部,默认前10行
head -n 15 ab.c # 显示文件ab.c前15行
head -n -20 msg.c # 除去文件尾部20行其余均算头部tail -n 40 liu.mail # 显示文件尾部20行
tail –n +20 msg.c # 除去文件头部20行其余均算尾部
tail -f debug.txt # 实时打印文件尾部被追加的内容(选项-f:forever)文本数据的处理
tee:三通
./myap | tee myap.log # 将从标准输入stdin得到的数据抄送到标准输出stdout显示,同时存入磁盘文件中
wc(word count)
wc sum.c # 列出文件一共有多少行,有多少个单词,多少字符
wc x.c makefile stat.sh # 除单个文件的行、单词、字符外,最后列出一个合计
wc -l *.c makefile start.sh # -l:只列出行数
sort
sort telno > telno1 # 对文件内容排序
ls -s | sort -n | tail -10 # -n:对于与数字按照算术值而不是字符串进行比较 ls -s:以文件大小排序
tr:翻译字符
cat report | tr ‘[a-z]’ ‘[A-Z]’ # 将小写字母改为大写字母
uniq
unique options input-file output-file # 筛选文件中的重复行
重复的行:紧邻的两行内容相同
选项:
- -u(unique)只保留没有重复的行
- -d(duplicated)只保留有重复的行(但只打印一次)
- 没有以上两个选项,打印没有重复的行和有重复的行(但只打印一次)
- -c(count)计数同样的行出现几次
正则表达式
正则表达式的概念
元字符和集合
- 非特殊字符与其自身匹配
- 转义字符(\). * $ \^ [ \
- 圆点(.)匹配任意单字符
定义集合
- 基本用法
- 单字符正则表达式[abcd]与a,b,c或d匹配
- 圆点、星号和反斜线在方括号内时,代表它们自己
- 用减号-定义一个区间
- 如[a-d] [A-Z] [a-zA-Z0-9]
- -在最后则仅表示自身,如[ab-]只与3个字符匹配
- 用^表示补集
- 单字符表达式后跟,匹配此单字符正则表达式的0次或*任意多次出现
锚点($与^)
- $在尾部时有特殊意义,否则与其自身匹配
- 例:123$匹配文件中行尾的123,.$匹配行尾的任意字符
- ^在首部时有特殊意义,否则与其自身匹配
- 表示分组:圆括号()
- 表示逻辑或的符号 |
重复次数定义
egerp:使用扩展正则表达式描述模式
- fgrep:快速搜索指定字符串(按字符串搜索而不是按模式搜索)

流编辑sed和正则表达式替换
基本用法:sed 选项 ‘脚本’ 文件名
选项:-e:执行脚本 -i:直接修改文件 -n:静默模式,只输出脚本处理后的结果sed ‘s/要替换的内容/替换后的内容/‘ 文件名 # 替换文本
sed ‘/要删除的内容/d’ # 删除行
sed -n ‘行号p’ # 打印行
sed -e ‘s/旧内容/新内容/g’ -e ‘s/另一个旧内容/另一个新内容/g’ 文件名 # 多个操作组合
在模式描述中,可以用括号 \( 和 \) 创建匹配组(capture groups),将匹配的文本片段捕获到一个临时缓冲区中,以便后续在替换操作或脚本中引用这些捕获组的内容。
将日期格式“月-日-年”改为“年.月.日”
比如:将 04-26-1997替换为1997.04.26使用命令:
s/\([0-9][0-9]\)-\([0-9][0-9]\)-\([0-9][0-9]*\)/\3.\1.\2/g
注意要先将三个/找到并进行划分
awk
基本用法:awk ‘模式{操作}’ 文件名
awk -f 脚本文件 文件名awk ‘模式’ 文件名 # 没有指定操作,会打印匹配模式的行
awk ‘{print}’ 文件名 # 打印文件的每一行
awk -F ‘,’ ‘{print $1,$2}’ 文件名 # -F指定不同的字段分隔符(默认为空格)
awk ‘{sum += $1} END {print sum}’ 文件名 # 计算文件中所有数字的总和(这里假设仅每行第一个字段为数字)
awk ‘{ if ($1 > 10) print $1 }’ 文件名 # 只打印大于10的数字文件比较
cmp
cmp file1 file2
逐字节比较两个文件是否完全相同
完全相同时不给出任何提示,否则打印出第一个不同之处
md5sum/sha1sum
md5sum/sha1sum filename
使用MD5算法/SHA-1算法根据文件内容生成16字节/20字节hash值
diff
diff file1 file2 # normal格式
diff -u file1 file2 # unified格式
diff -un file1 file2 # unified格式,显示不同行上下相同的各n行输出格式:
normal:add、change、delete
unified(-u):+ -vi编辑器
文件名和文件通配符
文件命名规则
- 一般允许1-255字符
- 除斜线外的所有字符都是命名的合法字符(斜线用作路径名分隔符)
- 大小写有区别
UNIX常见目录和文件
文件通配符规则
- *
- 匹配任意长度的文件名字符串
- 当点字符(.)作为文件名的第一个字符时,必须显式匹配。例:*file不匹配.profile
- ?
- 匹配任意单字符
- []
- 匹配括号内任意字符,也可以用-指定范围
- ~(Bash特有)
- ~:当前用户主目录
- ~kuan:kuan用户的主目录
注意:- 文件名通配符规则与正则表达式的规则不同,应用场合不同
- Windows中. 匹配所有文件,Linux中.\要求文件名中必须含有圆点,否则不匹配,如:*.*与makefile不匹配
文件通配符处理过程
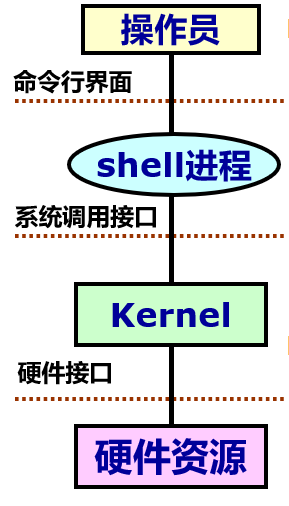
shell和kernel- shell
- shell是一个用户态进程,如/bin/bash
- 对用户提供命令行界面
- 启动其他应用程序(ap)
- 使用操作系统核心提供的功能:包括系统命令和用户编写的程序
- kernel
- 管理系统资源(包括内存,磁盘等)运行在核心态
- 通过软中断方式对用户态进程提供系统调用接口


shell文件名通配符处理
文件名通配符的处理由shell完成,分以下三步:
- 在shell提示符下,从键盘输入命令,被shell接受
- shell对所键入内容作若干加工处理,其中含有对文件通配符的展开工作(文件名生成),生成结果命令
- 执行前面生成的结果命令
文件管理和目录管理
列出文件目录
ls
ls
选项:
-F:Flag
-l:长格式列表
-h:human-readable,以便于人阅读的方式打印数值,如1K 234M
-d:列出目录自身的信息
-a:列出文件名首字符为圆点的文件
-A:同-a,但不列出.和..
-s:size,列出文件占用的磁盘空间
-i:i-node,列出文件的i节点号
ls -F
目录后缀/,可执行文件后缀*,符号连接文件后缀@,普通文件无标记> 
ls -l结果解释
-rwxr-x—x 1 liang stud 519 Jul 5 15:02 file1
- 第1列:文件属性
- 第1字符为文件属性
- 普通文件 b 块设备文件
d 目录文件 c 字符设备文件
l 符号连接文件 p 命名管道文件 - 文件的访问权限(rwx:读、写、执行)
依次为文件所有者、同组用户、其他用户对文件的权限
- 第1字符为文件属性
- 第2列:文件link数,涉及到此文件的目录项数
- 第3、4列:文件主的名字和组名
- 第5列:
- 普通磁盘文件:列出文件大小(字节数)
- 目录:列出目录表(存储目录信息的数据结构)大小,不是目录下文件长度和
- 符号连接文件:符号连接文件自身的长度
- 字符设备和块设备文件:列出主设备号和次设备号
- 管道文件:列出管道内的数据长度
- 第6列:文件最后一次被修改的日期和时间
- 第7列:文件名(对于符号连接文件,附带列出文件内容)
文件的复制与删除
cp
cp file1 file2 # 若file2不存在则创建,否则覆盖
cp file1 file2 … filen dir # dir必须已经存在并且是一个目录cp -r dir1 dir2 # -r递归地复制一个目录,dir2不存在则新建,拷入dir2;存在则拷入dir2/dir1
选项-v:冗长(verbose),复制目录时实时列出正在复制的文件的名字
选项-u:增量拷贝(update),根据文件的时戳,不拷贝相同的或者过时的版本的文件,以提高速度mv
mv file1 file2 # 改名
mv file1 file2 … filen dir # 移动文件
mv dir1 dir2 # dir2不存在->改名;dir2存在->移动目录rm
rm file1 file2 … filen # 删除文件
-r:递归地删除实参表中的目录
-i:每删除一个文件前需要操作员确认
-f:强制删除
显示区分命令选项和处理对象
问题:
设当前目录下只有a,b,c三个文件,
ls>-i # 生成文件-i
rm -i # 不能删除文件-i
rm * -> rm -i a b c # 将-i解析为选项
解决方法:
用—显式地表示命令行参数列表中选项的结束,例如rm — *,rm — -i
目录管理
pwd
print working directory
cd(change directory)
cd /usr/include
cd /
cd ..
cd # Windows中打印当前工作目录,unix中回到用户主目录
cd是shell的一个内部命令,在硬盘上没有存储,由shell自行完成mkdir/rmdir
mkdir sun/work.d
rmdir sun/work.d # 要求被删除的目录为空
rm -r sun/work.drsync
rsync 选项 源目录/文件 目标目录
选项:-a(归档模式,保留所有文件属性),-v、-r、-u
rsync用一精巧的算法,将文件分块,在两主机间传播数据块的hash值,具体推出两版本文件的区别,使得网络只传输增、删、改部分
目录遍历
find
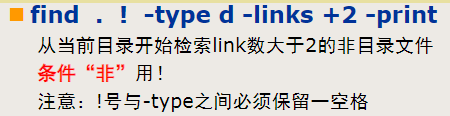
find 路径 匹配条件 动作
-name pattern:按文件名查找,支持使用通配符*和?
-type type:按文件类型查找,可以是f(普通文件)、d(目录)、l(符号连接)等
-size [+-]size[cwbkMG]:按文件大小查找,支持使用+/-表示大于或小于指定大小,单位可以是c(字节)、w(字数)、b(块数)、k(KB)、M(MB)或G(GB)
-mtime days:按修改时间查找,支持使用+/-表示在指定天数前或后,days是一个整数表示天数
-user/group name:按文件所有者/所有组查找可以用() -o !等表示多条件的“与”“或”“非”
-print:打印查找的文件的路径名
-exec:对查找到的目标执行某一命令,在-exec及随后的分号之间的内容作为一条命令,在这命令的命令参数中,{}代表遍历到的目标文件的路径名
-ok:与-exec类似,只是对查找到符合条件的目标执行一个命令前需要经过操作员确认目录遍历的应用
批量处理文件
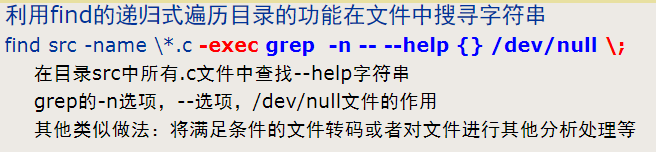
在目录src中所有.c文件中查找—help字符串
find src -name \*.c -exec grep -n -- --help {} /dev/null \;
缺点:效率低,因为每个命中的对象都需要创建一个进程执行grep命令find src -name \*.c -print | xargs grep -n -- --help
xargs命令从标准输入(stdin)读取数据,并将这些数据作为参数传递给其他命令。这使得xargs在处理大量数据时非常有用,尤其是当这些数据超出了单个命令行的最大参数限制时。打包与压缩
tar
tar ctxv[f device] file-list
选项第一字母指定要执行的操作
c:Create创建新磁带。从头开始写,以前存于磁带上的数据会被覆盖掉
t:Table列表。磁带上的文件名列表,当不指定文件名时,将列出所有的文件
x:eXtract抽取。从磁带中抽取指定的文件。当不指定文件名时,抽取所有文件除功能字母外的其它选项
v:Verbose冗长。每处理一个文件,就打印出文件的文件名,并在该名前冠以功能字母
f:File。指定设备文件名
z:采用压缩格式(gzip算法)
j:采用压缩格式(bzip2算法)



tar的使用:磁带机操作
- tar cvf /dev/rct0 .
将当前目录树备份到设备/dev/rct0中,圆点目录是当前目录 - tar tvf /dev/rct0
查看磁带设备/dev/rct0上的文件目录 - tar xvf /dev/rct0
将磁带设备/dev/rct0上的文件恢复到文件系统中
tar的使用:文件打包
tar cvf my.tar *.[ch] makefile
指定普通文件代替设备文件,将多个文件或目录树存储成一个文件。这是UNIX世界早期最常用的文件和目录打包工具
tar的使用:目录打包
设work是一个有多个层次的子目录 - tar cvf work.tar work
- tar cvzf work.tar.gz work (gzip压缩算法,对C程序体积为原来的20%)
- tar cvjf work.tar.bz2 work(bzip2压缩算法,对C程序17%,执行时间三倍)
查看归档文件中的文件目录: - tar tvf work.tar.gz
从归档文件中恢复目录树: - tar xvf work.tar.gz
文件名后缀.tar,.tar.gz,.tar.bz2仅仅是惯例,不是系统级强制要求
文件压缩和解压缩
gzip/gunzip (执行速度快)
bzip2/bunzip2 (占用较多的CPU时间)应用程序获取信息的方法
命令获取信息的方法
- Linux系统命令和用户程序都属于用户态程序,运行时需要获取的信息包括配置信息、处理方式(选项参数)、被处理的对象
- 硬编码需要编程时就确定服务器的地址,程序运行时就无法改变,太不灵活
- 运行时获取信息的常见方式(易变性从小到大)
- 配置文件
- 环境变量
- 命令行参数
- 交互式键盘输入
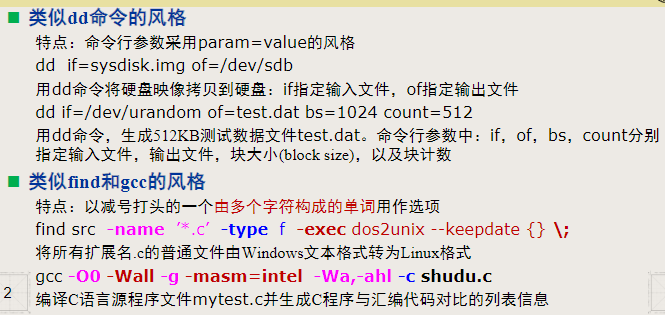
命令行参数的三种风格

文件系统
文件系统的创建与安装
根文件系统和子文件系统
根文件系统(root filesystem)是整个文件系统的基础,不能“脱卸(umount)”
子文件系统(包括硬盘、软盘、CD-ROM、USB盘、网络文件系统NFS)以根文件系统中某一子目录的身份出现
根文件系统和子文件系统都有其自己独立的文件系统存储结构,甚至文件系统的格式也不同。文件系统的创建、安装和卸载
mkfs /dev/sdb
块设备文件/dev/sdb上创建文件系统mount /dev/sdb /mnt
/mnt可以是任一个事先建好的空目录名,允许处于根文件系统的任何目录中,此后,操作子目录/mnt就是对子文件系统的访问mount
列出当前已安装的所有子文件系统umount /dev/sdb
卸载已安装的子文件系统/dev/sdbdf
查看文件系统空闲空间,选项-h(human-readable)文件系统的存储结构
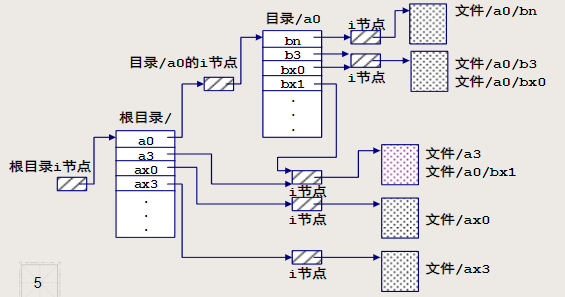
文件系统的结构
把整个逻辑设备以块为单位划分,编号为0、1、2…(每块512字节或更大2^n字节大小)
- 引导块(0号块):用于启动系统,只有根文件系统的引导块有效
- 专用块(1号块):也叫管理块,或者超级块,存放文件系统的管理信息。如:文件系统的大小,i节点区的大小,空闲空间大小,空闲块链表的头等等
- i节点区:
- 由若干块构成,在mkfs命令创建文件系统时确定,每块可容若干i节点,每个i节点的大小是固定的(比如64节点)
- i节点从0开始编号,根据编号可以索引到磁盘块
- 每个文件都对应一个i节点,i节点中的信息包括:指向文件存储区数据块的一些索引指针、文件类型、属主、组、权限、link数、大小、时戳(不含文件名)
- 文件存储区:用于存放文件数据,包括目录表
目录的存储结构
Linux目录结构是树形带交叉勾连的目录结构
目录表 - 每个目录表也作为一个文件来管理,存于文件存储区中国,有其自身的i节点和数据存储块
- 目录表由若干个“目录项”构成,目录项只包含两部分信息:文件名、i节点号
- 用ls命令列出的目录大小是目录表文件本身的大小
硬链接
硬链接数目(link数):同一i节点被目录项引用的次数ln:普通文件的硬链接
- 对于普通文件来说,硬连接数表示有多少不同的文件名指向同一块数据
- 当创建一个新文件时,它的硬链接数通常是1。如果为该文件创建了额外的硬链接,其链接数会相应增加
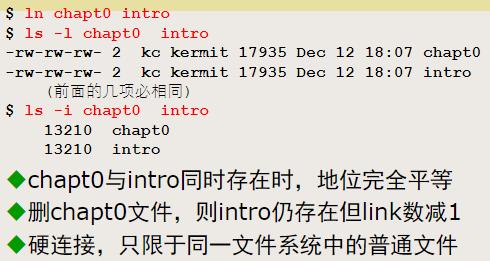
目录表的硬链接
- 不允许对目录用ln命令建立硬连接
- 一般来说,目录的link数=直属子目录数+2(每个目录都有两个固定的引用:目录本身的名字和目录中的.)
符号链接
符号链接也叫软链接,用特殊文件“符号连接文件”来实现,文件中仅包含了一个路径名
符号链接的实现
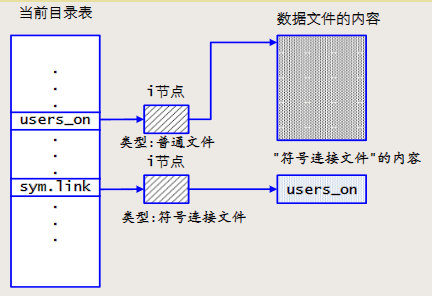
符号链接中的相对路径
- 若符号链接包含绝对路径名,引用绝对路径名
- 若符号链接包含相对路径名,是相对于符号链接文件的位置
硬链接和符号链接的比较
硬链接 - 在数据结构层次上实现
- 只适用于文件,不适用于目录
- 不同文件系统之间也不行
- 硬链接能够完成的功能软连接也可以做到
符号链接 - 在算法软件上实现
- 硬链接能够完成的功能软连接都可以做到
- 适用于目录,也适用于不同的文件系统
- 同硬连接相比要占用操作系统内核的一部分开销
系统调用
- 系统调用以C语言函数调用的方式提供,是应用程序和操作系统进行交互的唯一手段
- 系统调用与库函数在执行方式上的区别:CPU的INT指令(软中断)与CALL指令(子程序调用)
- 库函数对系统调用进行封装(API),使执行效率更高或者调用界面更方便,例如printf对write的封装,malloc/free对sbrk的封装
- 系统调用函数的返回值一般为一个整数,大于或等于0表示成功,返回值为-1表示失败
整型变量errno与库函数strerror
- 标准库为errno保留存储空间,系统调用失败后填写错误代码,记录失败原因,#include
之后,可以直接使用变量errno char *strerror(int errno),errno是个整数,便于程序识别错误原因,不便于操作员理解失败原因,库函数strerror将数字形式的错误代码转换成一个可阅读的字符串print("ERROR %d:%m\n", errno),printf类函数格式字符串中的%m会被替换成上次系统调用失败的错误代码对应的消息访问i节点和目录
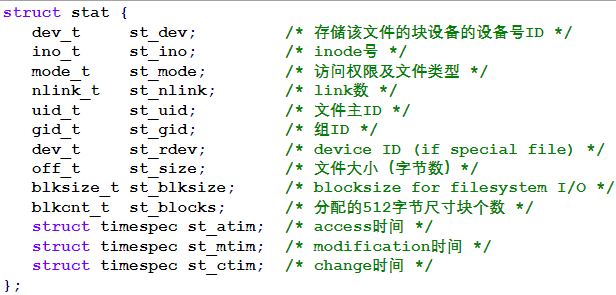
系统调用stat/fstat:从i节点获得文件的状态信息
int stat(const char *pathname, struct stat *buf)
stat得到指定路径名的文件的i节点int fstat(int fd, struct stat *buf)
fstat得到已打开文件的i节点结构体stat
目录访问
早期的UNIX像普通磁盘文件那样open()打开目录read()读取,现在的系统不再这样操作,而是直接使用封装好的库函数#include<dirent.h>DIR *opendir(char *dirname);struct dirent *readdir(DIR *dir);int closedir(DIR *dir)- opendir打开目录得到句柄
- readdir获取一个目录项
- 返回值指向dirent结构体
- dirent结构体记录i节点号和文件名
- closedir关闭不再使用的目录句柄,访问结束
文件和目录的权限
文件的权限
文件的权限用于控制进程对系统中文件和目录的访问 - 权限的三个级别
- 文件主,同组用户,其他用户
- 每个文件有唯一的属主
- 普通文件的权限
- 读、写、可执行
- 不可写文件也可能会被删除(需要看目录有没有写权限)
两类可执行文件
- 程序文件(可执行文件)
- 二进制的CPU指令集合
- 脚本文件(文本文件)
- 读权限
- 拥有读权限的用户可以使用 ls 命令来查看该目录中的文件和子目录列表。
- 目录的读权限并不允许用户查看目录中文件的具体内容;查看文件内容需要对那些文件具有读权限。
- 拥有目录的读权限并不意味着可以进入目录。进入目录需要该目录的执行权限(x)。
- 写权限
- 若无写权限,那么目录表不许写(不许创建/删除文件)
- 修改文件不需要修改目录文件,需要修改i节点
- 执行权限
- 有执行权限意味着允许用户进入目录
- cat /a/b/c,要求/a与a/b目录有x权限,c文件有读权限
- cd ../st8,要求当前目录,..和st8必须有x权限
- STICKY权限(粘着位)
- 早期Unix具有sticky属性的可执行文件尽量常驻内存或交换区以提高效率。现代Linux对访问过的文件自动缓冲在内存,文件sticky属性被忽略
- 对于公共目录下,用户user1和user2没有写权限就不能创建文件,若有写权限,用户user1的文件就算是只读文件也可以被user2删除。STICKY属性用于解决这个问题:目录有写权限并且带STICKY属性,此目录下的文件仅文件主可以删除,其他用户删除操作会失败。
权限验证的顺序
每个文件都有文件主和组的属性(文件节点中)
每个进程也有进程主和组的属性(进程PCB中)
都是整数,uid和gid的编号与名字的对应关系见/etc下passwd和group文件
例:chmod go-rwx *.[ch] 对所有c语言源程序文件,不允许其他用户读、写和执行
chmod:修改权限(数字形式)
例:chmod 644 xyz1 xyz2
八进制: 6 4 4
二进制:110 100 100
权限:rw- r— r—
注意:只有文件主和超级用户修改文件权限
umask:决定文件/目录的初始权限
umask是shell内部命令,是进程属性的一部分
umask:打印当前的umask值
umask 022:将umask值设置为八进制的022(二进制为000 010 000,取消新文件和新目录的组w权限和其他用户w权限)
一般将umask命令放到shell自动执行的批处理文件中。
系统调用umask可以修改进程自身的umask属性值,初创文件的权限受open的规定值进程自身属性umask值影响。已存在的文件的权限,不受open/umask的影响。
三级权限存在的问题
问题:系统中任一个用户,要么对文件的全部内容具有访问权,要么不可访问文件。有的情况下,很不方便。例如用户修改口令,需要访问和修改文件/etc/passwd。
解决方法:SUID权限
- 当一个可执行文件设置了 SUID 权限后,无论谁运行这个文件,该程序都会以文件所有者的权限来执行。
- 例如,如果一个可执行文件的所有者是 root,并且设置了 SUID 权限,那么无论谁运行这个程序,该程序都会以 root 用户的权限来运行。
- SUID 通常用于那些需要提高权限以执行特定任务的程序。例如,passwd程序用于更改用户的密码,需要访问通常只有 root 用户才能访问的系统文件。通过设置 SUID 权限,普通用户在运行 passwd程序时能以 root 用户的身份执行,从而可以更新密码文件。
shell的基本机制
shell概述
shell种类
- B-shell
- C-shell
- K-shell
- /bin/bash(inux上的标准shell)
shell的功能
- shell是命令解释器
- 文件名替换,命令替换,变量替换
- 历史替换(上下方向键查看历史指令),别名替换
- 流程控制的内部命令
shell的特点
- 主要用途:批处理,执行效率比算法预言低
- shell编程风格和C语言等算法语言的区别
- shell是面向命令处理的语言,提供的流程控制结构通过对一些内部命令的解释实现
- shell许多灵活的功能,通过shell替换实现,例如:流程控制所需的条件判断,四则运算,都由shell之外的命令完成
bash的启动
三种启动方法
- 将登陆后执行的shell设置为bash:注册shell
- 键入bash命令:交互式shell
- 脚本解释器
自动执行的一批命令
用户级 - 当bash作为注册shell被启动时:自动执行用户主目录下的.bash_profile文件中命令,记作:~/.bash_profile或$HOME/.bash_profile。或~/.profile
- 当bash作为注册shell退出时:自动执行$HOME/.bash_logout
- 当bash作为交互式shell启动时:自动执行$HOME/.bashrc
- 类似umask之类的命令,应当写在.bash_profile文件中
系统级 - 当bash作为注册shell被启动时:自动执行/etc/profile文件中命令
- 当bash作为交互式shell启动时:自动执行/etc/bash.bashrc
- 当bash作为注册shell退出时:自动执行/etc/bash.bash.logout
脚本文件
编辑文件lsdir,文件名不必须为.sh后缀,只是个惯例if [$# = 0] # 检查命令行参数的个数thendir=.elsedir=$1 # 变量dir赋值为命令行第一个参数fi # if语句的结束,相当于end iffind $dir -type d -print # 打印dir的目录树echo '------------'cd $dirpwd脚本文件的执行
- 新创建子进程,并在子进程中执行脚本
- bash<\lsdir 无法携带命令行参数
- bash lsdir
bash -x lsdir (调试运行,指令命令之前打印出每个命令及其扩展的参数)
bash lsdir /usr/lib/gcc - 给文件设置可执行属性x,然后执行:chmod u+x lsdir ./lsdir /usr/lib/gcc
- 在当前shell进程中执行脚本:. lsdir /usr/lib/gcc 或者 source lsdir /usr/lib/gcc (脚本执行后对当前shell状态有影响)
历史与别名
历史表
- 先前键入的命令存于历史表,编号递增,FIFO刷新
- 表大小由变量HISTSIZE设定,修改HISTSIZE的配置应放入~/.bashrc
查看历史表
- 内部指令history(文件~/.bash_history)
历史替换
- 人机交互时直接使用上下箭头
- 其他方法:!! 引用上一命令 !str 以str开头的最近使用过的命令,如!v !m !.
别名
别名替换
- 在别名表中增加一个别名(内部命令alias)
如:alias p=’ping 202.143.12.189’
alias rm=‘rm -i’ 对rm命令进行重载
如果需要,应把alias命令放入.bashrc - 查看别名表 alias
- 取消别名(内部命令unalias)
unalias n 在别名表中取消nTAB键补全
- 每行的首个单词
TAB键补全搜索$PATH下的命令 - 行中的其它单词
TAB键补全当前目录下的文件名输入重定向
- <\filename
从文件filename中获取stdin,例如:sort<telno.txt - <\<word
从shell脚本文件获取数据直到再次遇到定界符work,定界符两侧加单引号:不允许定界符之间的内容进行替换操作(如‘date’、$HOME) - <<\<word
从命令行获取信息作为标准输入输出重定向与管道
程序的标准输入/输出
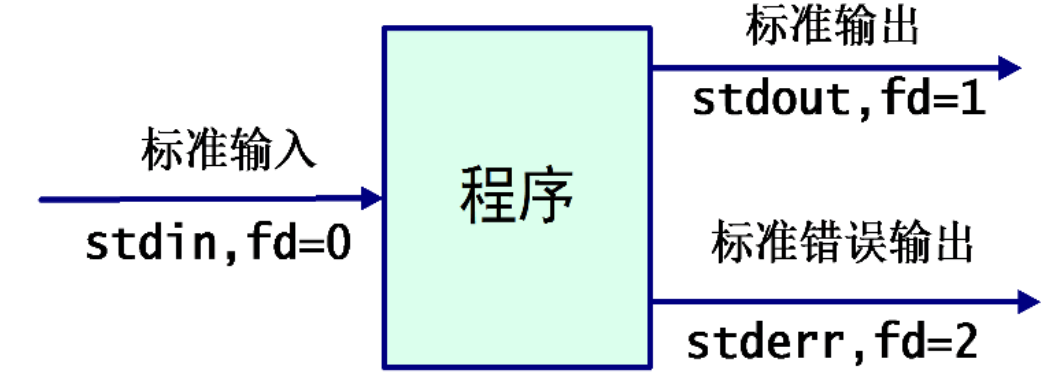
stdout输出重定向
- >filename
将stdout重定向到文件filename,文件已存在则先清空(覆盖方式) - >>filename
将stdout重定向追加到文件filenamestderr输出重定向
- 2>filename
将文件句柄2重定向到文件filename,分离stdout与stderr的意义 - 2>&1
将文件句柄2重定向到文件描述符1指向的文件,允许对除0,1,2外其它文件句柄输入或输出重定向输出重定向例子
- ls -l > file.list
将命令ls标准输出stdout定向到文件file.list中 - cc try.c -o try 2 > try.err
将cc命令的stderr重定向到文件try.err中 - try > try.out 2>try.err
try 1 >try.out 2>try.err
将try程序执行后的stdout和stderr分别重定向到不同的文件 - ./stda >rpt 2>&1
stdout和stderr均存入文件rpt - ./ stda 2>&1 >rpt
stderr定向到终端,stdout重定向到文件管道
- ls -l | grep ‘^d’
前一命令的stdout作后一命令的stdin - cc try.c -o try 2>&1 | more
前一命令的stdout+stderr作为下一命令的stdin变量
变量的赋值及使用
bash变量
- 存储的内容
- 字符串(对于数字串来说,不是二进制形式)
- 在执行过程中其内容可以被修改
- 变量名
- 第一个字符必须为字母
- 其余字符可以是字母,数字,下划线
- 赋值与引用
- addr=20.1.1.254 注意:赋值作为单独一条命令,等号两侧不许多余空格
- 引用addr变量的方法:$addr或${addr}
- 命令行中含有$符的变量引用,shell会先完成变量替换
- 赋值时,等号右侧字符串中含有特殊字符要用双引号,如unit=”Beiyou University”
- 引用未定义变量,变量值为空字符串
- shell内部开关
缺点:在不同Unix之间兼容性差
在脚本中编辑文件
read
内部命令read:变量取值的另外一种方法
- 从标准输入读入一行内容赋值给变量,例:read name
ed
ed 选项 filename
单行纯文本编辑器
内置命令:A:切换到输入模式,在文件最后一行之后输入新的内容 C:切换到输入模式,用输入的内容替换掉最后一行的内容 i:切换到输入模式,在当前行之前加入一个新的空行来输入内容 d:用于删除最后一行文本内容 n:用于显示最后一行的行号和内容 w:\<文件名>:以给定的文件保存当前正在编辑的文件 q:退出ed编辑器环境变量
环境变量和局部变量
默认类型
- 所创建的shell变量,默认为局部变量
内部命令export
- 局部变量转换为环境变量,例如export proto
局部变量和环境变量
- shell启动的子进程继承环境变量,不继承局部变量
- 子进程对环境变量的修改,不影响父进程中同名变量
- 环境变量的设置,如PATH,CLASSPATH,LANG,若有必要放在~/.bashrc中或/etc/profile中
系统的环境变量
创建
- 登陆后系统自动创建一些环境变量影响应用程序运行
HOME:用户主目录的路径名
PATH:指定系统在查找可执行文件(命令)时应搜索的目录列表
- PATH=/bin:/usr/bin:/etc
- 与DOS/Windows不同的是,它不首先搜索当前目录
- PATH=.:/bin:/usr/bin:/etc先搜索当前目录(危险:可能会执行到恶意程序)
- PATH=/bin:/usr/bin:/etc:.后搜索当前目录(危险:可能会执行到恶意程序)
相关命令set/env
- 内部命令set列出当前所有变量及其值以及函数(包括环境变量和局部变量、函数定义)
set|grep^fname= - 外部命令/bin/env列出环境变量及其值
环境变量的引用
- 脚本程序可直接引用环境变量值(脚本程序由当前子shell解释执行,而环境变量可继承)
- C程序可以通过函数getenv()引用环境变量
替换
shell替换
shell的替换工作:先替换命令行再执行命令 - 文件名生成
- 变量替换
- 命令替换
变量替换
- ls $HOME
- echo ”My home is $HOME,Terminal is $TERM”
文件名生成
- 遵循文件通配符规则,按照字典序排列
如:ls *.c文件名替换后实际执行lsa.cx.c - 无匹配文件:保持原文,例如:*.php展开后还是*.php
例如:vi *.php命令替换
- 反撇号方式
now=`date` //以命令date的stdout替换`date`
ts=`date’+%Y%m%d-%H%M%S’`;
mv myap.log `whoami`-$ts.log //用户名加时间戳做文件名
frames=`expr 5+13`
- $()格式(与反撇号方式类似)
now=$(date)
ts=$(date’+%Y%m%d-%H%M%S’);
mv myap.log $(whoami)-$ts.log
frames=$(expr 5+13)
shell内部变量:位置参数
- $0 脚本文件本身的名字
- $1$2 1号命令行参数,2号命令行参数,以此类推
- $# 命令行参数的个数
- ”$*” 等同于”$1 $2 $3 $4…”
- ”$@” 等同于”$1” ”$2” ”$3”…
- 内部命令shift:位置参数的移位操作,$#的值减1,旧的$2变为$1,旧的$3变为$2,以此类推
其他用法如:shift3(移位三个位置)元字符和转义
元字符
空格,制表符 命令行参数的分隔符
回车 执行键入的命令
><| 重定向与管道(还有||)
; 用于一行内输入多个命令(还有;;)
& 后台运行(还有&&)
$ 引用shell变量
` 反向单引号,用于命令替换
*[]? 文件通配符(echo”*“与echo*不同)
\ 取消后继字符的特殊作用(转义)
() 用于定义shell函数或在子shell中执行一组命令转义
反斜线
- 反斜线作转义符,取消其后元字符的特殊作用
- 如果反斜线加在非元字符前面,反斜线跟没有一样
find / -size +100 \(-name core -o -name \*.tmp\) -exec rm -f {}\;
ls-l>file\ list 文件名中包含空格
echo *与echo \*
单引号和双引号
- 双引号”括起来的内容,除$和`外特殊字符的特殊含义被取消(保留一定的灵活性)
- 单引号‘括起来的内容,任何字符不作特殊解释
shell流程控制:条件
shell中的逻辑判断
shell中的条件判断
命令执行的返回码为0表示成功,非0表示失败,可以把返回码理解为”出错代码“。
如果代码中main()函数没有return一个确定的值,返回码就是随机值,不可用来做条件判断。shell内部变量$?
值为上一命令的返回码,例如:
$ ls -d xyz
xyz
$ echo $?
0
注:用管道线连接在一起的若干命令,进行条件判断时以最后一个命令执行的返回码为准复合逻辑
用&&或||连结两个命令
可以利用复合逻辑中的“短路计算”特性实现最简单的条件 - cmd1&&cmd2
若cmd1执行成功(返回码为0)则执行cmd2,否则不执行cmd2 - cmd1||cmd2
cmd1执行失败(返回码不为0)则执行cmd2,否则不执行cmd2
若没有目录ydir
$ ls -d ydir >/dev/null 2>&1 || echo No ydir
No ydir
命令true与false
- /bin/true
返回码总为0 - /bin/false
返回码总不为0 - 有的shell为了提高效率,将true和false设置为内部命令
test命令和方括号命令
命令test与[
- 用于检查某个条件是否成立,并根据这个条件的结果返回退出状态。退出状态为 0 表示条件为真,非 0 表示条件为假。
- 命令/usr/bin/[要求其最后一个命令行参数必须为]
- 除此之外/usr/bin/[与/usr/bin/test功能相同
有的Linux系统中/usr/bin/[是一个指向test的符号连接 - 注意:不要将方括号理解成一个词法符号
- 举例
test -r /etc/motd
[ -r/etc/motd ] [是命令,]是参数。空格不能省略文件特性检测
-f 普通文件 -d 目录文件
-r 可读 -w 可写
-x 可执行 -s size>0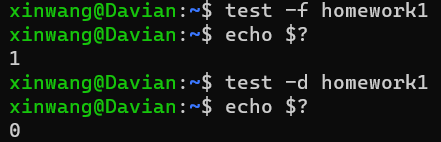
字符串比较
str1= str2 str1与str2串相等(bash也允许以\==代替=)
str1!=str2 str1串与str2串不等
注意:等号和不等号两侧的空格不可少
[ “$a”=”” ] && echo empty string 注意:$a的引号
test $# = 0 && echo”No argument”
level=8
[ $level=0 ] && echo level is Zero
应为
[ $level = 0 ] && echo level is Zero
[ $level=0 ]仅判断$level=0是否为空字符串,非空即返回0
整数的比较
-eq= -ne ≠
-gt> -ge≥
-lt< -le≤
例:
test `ls | wc -l` -ge 100 && echo”Too many files”
复合条件
! NOT(非)
-o OR(或)
-a AND(与)
例:如果变量cmd的值为一个可执行命令,执行该命令
[ ! -d $cmd -a -x $cmd ] && $cmd
注意:必需的空格不可省略
命令组合
命令组合的两种方式{}与()
命令组合类似C语言中的复合语句,组合在一起的几个命令作为一个整体看待:可以集体管道和重定向或者当条件满足时执行若干个命令。
1 | pwd |
{}与()的不同
语义上的不同
{}在当前shell中执行一组命令
()在子shell中执行一组命令
例如,上述代码中,第二次pwd结果应为/usr/bin,假如将花括号换为圆括号,结果应与第一次pwd结果相同
语法上的不同
(list)在子shell中执行命令表list
{ list;}在当前shell中执行命令表list
- 注意:左花括号后面必须有一个空格
- 圆括号是shell元字符,花括号不是,它作为一个特殊内部命令处理。所以必须是一行的行首单词
条件分支
条件结构if:两个或多个分支
其中:if/then/elif/else/fi为关键字(内部命令),关键字作为内部命令,要么在行首,要么前面有分号来分隔命令1
2
3
4
5
6
7
8
9if condition
then
list
elif condition
then
list
else
list
fi
与C语言不同,if的语法中then与else或fi配对,使得不需要花括号这样的命令组合case结构:多条件分支
1
2
3
4
5
6
7case word in
pattern1)
list1;;
pattern2)
list2;;
...
esac - word与pattern匹配:使用shell的文件名匹配规则
- ;;是一个整体,不能在两分号间加空格,也不能用两个连续的空行代替
- word与多个模式匹配时,执行遇到的第一个命令表
shell脚本中的注释
shell中使用#号作注释
#号出现在一个单词的首部,那么,从#号至行尾的所有字符被忽略shell流程控制:循环
表达式计算
- shell不支持除字符串以外的数据类型,不支持加减乘除等算数运算和关于字符串的正则表达式运算
- 需要这些功能,借助于shell之外的可执行程序/usr/bin/expr实现
- 有的shell(包括bash)为了提高执行效率,提供内部命令版本的echo,printf,expr,test,[等命令,但这仅仅是一种性能优化措施。只依赖外部命令完全可以实现
expr
括号:()
算术运算:+ - * / %
关系运算:> >= <= = !=
逻辑运算:| &
正则表达式运算: :空格与转义
- 应该转义的地方必须加反斜线转义
- 应该有空格的地方不允许漏掉

正则表达式运算
用法:expr string : pattern - 正则表达式pattern匹配字符串string,打印匹配长度
- attern中用\(和\)括起一部分,能匹配时打印括号内能匹配的部分,否则为空字符串

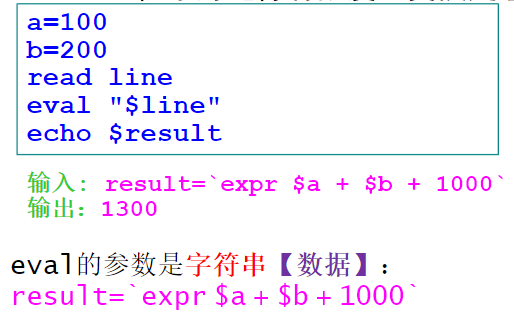
内部命令eval
将程序中输入的或者加工出来的数据作为程序来执行 - 解释和编译
- 将数据(程序生成的数据或者外部输入的数据)当做程序来执行是只有解释型语言才可能具备的特点,类似C这样的编译型语言无法具备这样的功能(但可以通过“动态链接”的方式,在程序运行期间不停止程序的运行有限度地变换处理程序)
while循环
1
2
3
4while condition
do
list
donefor循环
for
1
2
3
4
5
6
7
8
9
10
11
12
13
14for name in word1 word2 ...
do
list
done
或者
for name
do
list
done
相当于
for name in $1 $2 ...
do
list
doneseq
用seq命令实现类似C语言中的for循环人机交互时可直接写为一行:1
2
3
4for i in \`seq 1 254\`
do
ping -c 1 -w 1 192.168.0.$i
done
for i in `seq1254`;do ping -c1 -w1 192.168.0.$i;donebreak,continue,exit
内部命令break
循环结构for/while中使用,中止循环
例:break
break2 # 中止两重循环内部命令continue
在循环结构for/while中使用,提前结束本轮循环内部命令exit
结束脚本程序的执行,退出。exit的参数为该进程执行结束后的返回码
例:exit 1shell流程控制:函数
语法:
name() { list; }- 程序的CPU指令代码,包括:主程序和子程序编译后的CPU指令代码,以及调用的库函数代码
- 指令段的大小固定不变,只读
用户数据段
- 全局变量,静态变量,字符串常数
- 允许数据段增长和缩小,实现内存的动态分配
用户栈段
- 程序执行所需要的栈空间,实现函数的调用
- 保存子程序返回地址
- 在函数和被调函数之间传递参数
- 函数体内部定义的变量(静态变量除外)
- main函数得到的命令行参数以及环境参数
- 存放在栈的最底部
- main函数运行之前,这些部分就已经被系统初始化
- 栈段的动态增长与增长限制
系统数据段
- 上述三部分在进程私有的独立地逻辑地址空间内(CPU用户态访问)
- 系统数据段是内核内的数据,每个进程对应一套
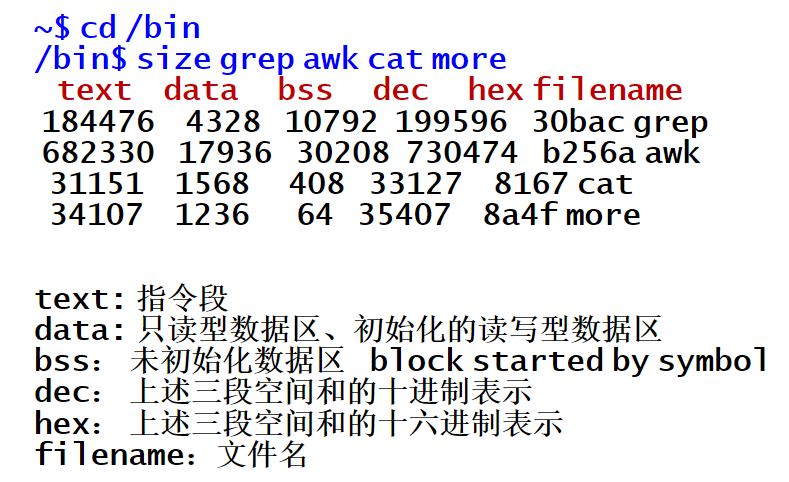
进程虚拟地址空间的布局
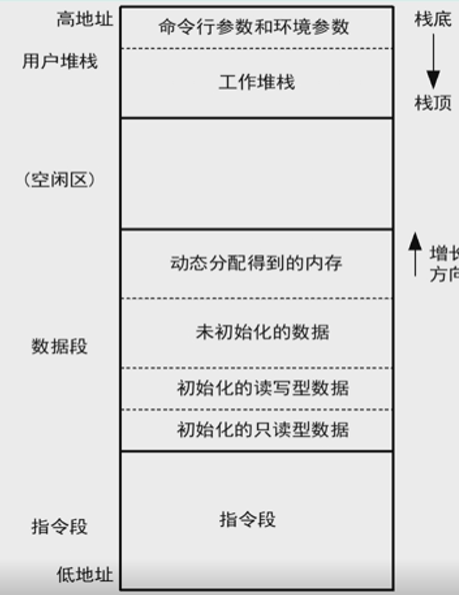
逻辑地址和物理地址间的转换
略,操作系统课程中有详细内容
进程的执行状态
进程的系统数据
在UNIX内核中,含有进程的属性,包括:
- 页表
- 进程状态,优先级信息
- 核心堆栈
- 当前目录(记录了当前目录的i-节点),根目录
- 打开的文件描述符表
- umask值
- 进程PID,PPID
- 进程主的实际UID/GID,有效UID/GID
- 进程组组号
传统UNIX的user+proc结构
进程PCB被分为user结构和proc结构两部分 - user结构(约5000字节),
- 进程运行时才需要的数据在user结构
- 核心态堆栈占用了较多空间
- proc结构(约300字节),
- 进程不运行时也需要的管理信息存于proc
- 用户程序不能直接存取和修改进程的系统数据
- 系统调用可用来访问或修改这些属性
- 内核将可运行进程按优先级调度,高优先级进程优先;
- 进程的优先级总在不停的发生变化;
- 处于睡眠状态的进程一旦被叫醒后,被赋以高优先级,以保证人机会话操作和其它外设的响应速度;
- 用户程序用nice()系统调用有限地调整进程的优先级。
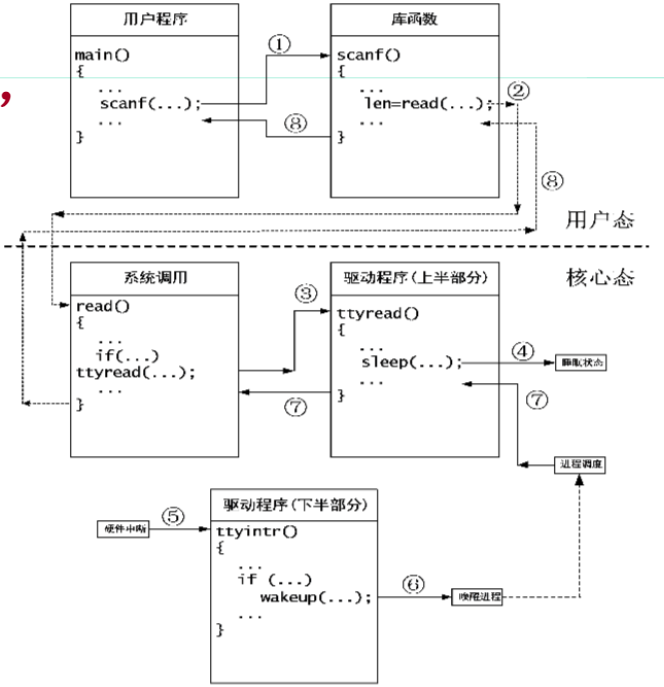
系统调用的过程示例
进程的执行时间
进程执行时间包括睡眠时间,CPU时间(用户时间和系统时间)time

系统调用times

与时间有关的函数
标准函数库中time():获得当前时间坐标 - 坐标0为1970年1月1日零点,单位:秒
- t=time(0);和time(&t);都会使t值为当前时间坐标
函数gettimeofday()
- 获得当前时间坐标,坐标的0是1970年1月1日零点
- 可以精确到微秒μs(10-6秒)
mktime
- 将年月日时分秒转换为坐标值
ctime()和asctime(),localtime()
- 坐标值和年月日时分秒转换
strftime
- 定制表示日期和时间的字符串(包括年月日时分秒等)
忙等待
在忙等待中,一个进程或线程反复检查某个条件是否满足,而不进行其他操作或改变状态。多任务系统中”忙等待“的程序是不可取的。进程的创建和重定向
进程的生命周期
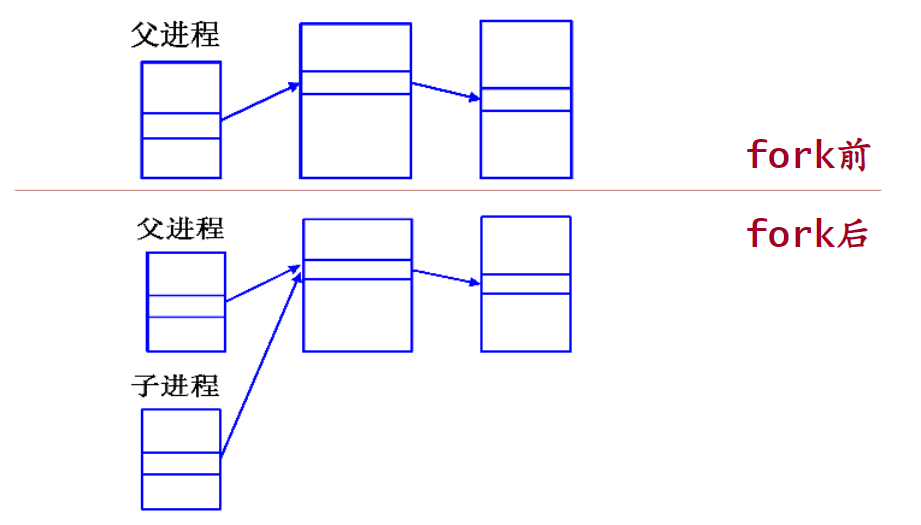
回顾:进程的系统数据fork:创建新进程
功能: - fork系统调用可以创建新进程,原先的进程称作父进程,新创建进程被称作子进程
- 完全复制:新进程的指令,用户数据段,堆栈段
- 部分复制:系统数据段
fork返回值: - 父进程返回值>0,是进程的PID
- 子进程返回值=0,失败时返回-1
内核实现: - 创建新的PCB,复制父进程环境(包括PCB和内存资源)给子进程
- 父子进程可以共享程序和数据(例如:copy-on-write技术)
命令行参数和环境参数
命令行参数和环境参数是位于进程堆栈底部的初始化数据。 - 访问命令行参数的方法(argc,argv)
- 访问环境参数的三种方法
- 用一个指定的程序文件,重新初始化一个进程
- 可指定新的命令行参数和环境参数(初始化堆栈底部)
- exec不创建新进程,只是将当前进程重新初始化了指令段和用户数据段,堆栈段以及CPU的PC指针
6种格式exec系统调用:
exec前缀,后跟一至两个字母(l-list, v-vector,e-env, p-path) - l与v:指定命令行参数的两种方式,l以表的形式,v要事先组织成一个指针数组
- e:需要指定envp来初始化进程
- p:使用环境变量PATH查找可执行文件

wait系统调用
功能: - 等待进程的子进程终止(”收尸“)
- 如果已经有子进程终止,则立即返回
函数返回值为已终止的子进程PID僵尸进程(zombie或defunct)
当一个进程已经完成执行(即已经结束),但其父进程尚未通过调用wait()系统调用来读取其终止状态时,这个已结束的进程就变成了僵尸进程。 - 系统已经释放了进程占用的包括内存在内的系统资源,但仍在内核中保留进程的部分数据结构,记录进程的终止状态,等待父进程来”收尸“。
- 僵尸进程占用资源很少,仅占用内核进程表资源,过多的僵尸进程会导致系统有限数目的进程表被用光。
自编shell:xsh0
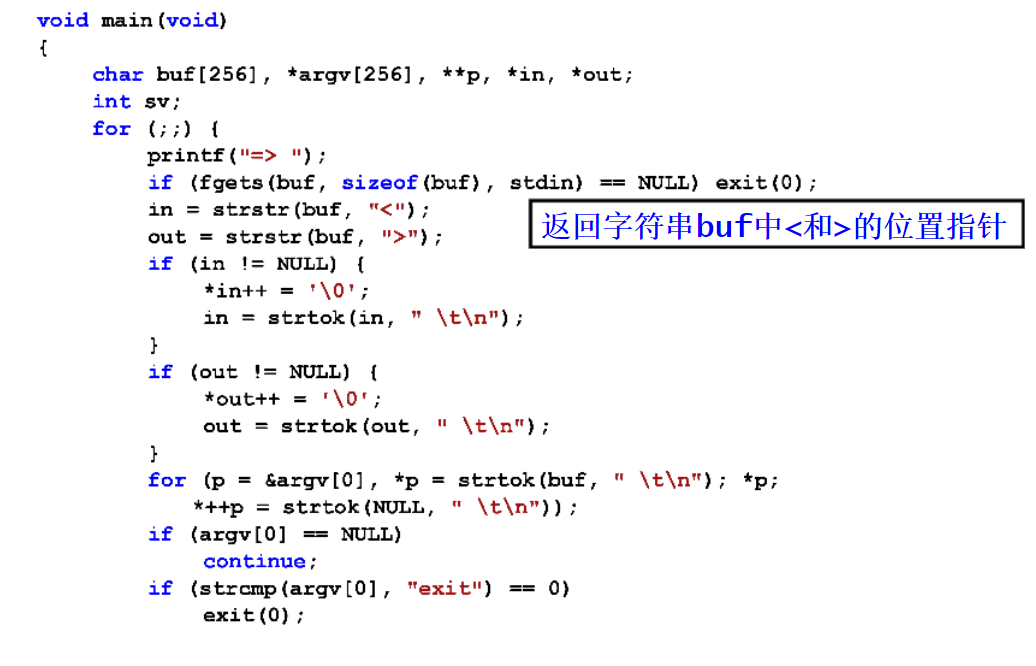
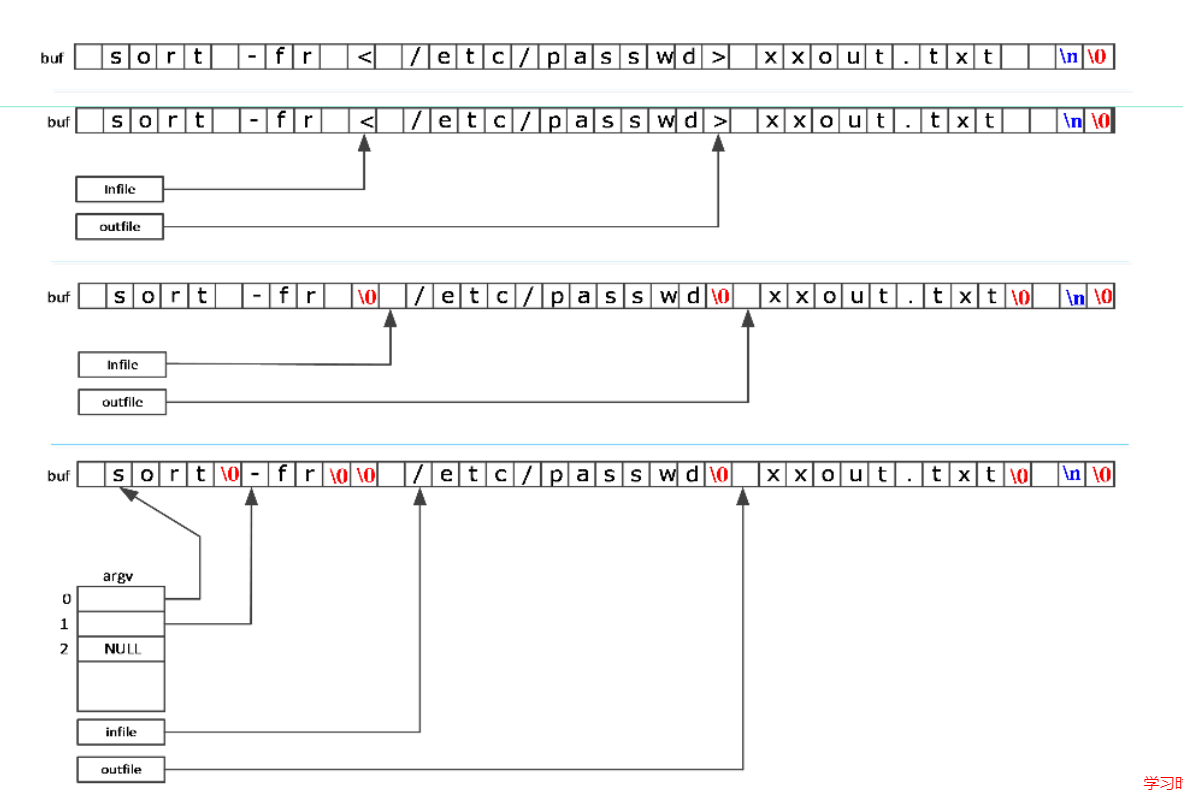
字符串库函数strtok
char *strtok(char *str,char *tokens)
功能:返回第一个单词的首字节指针
示例:
- 空格、制表符、换行都作为字符串结束标识
- NULL指示继续分割
- 无从分割则返回NULL
最简单的shell:xsh0

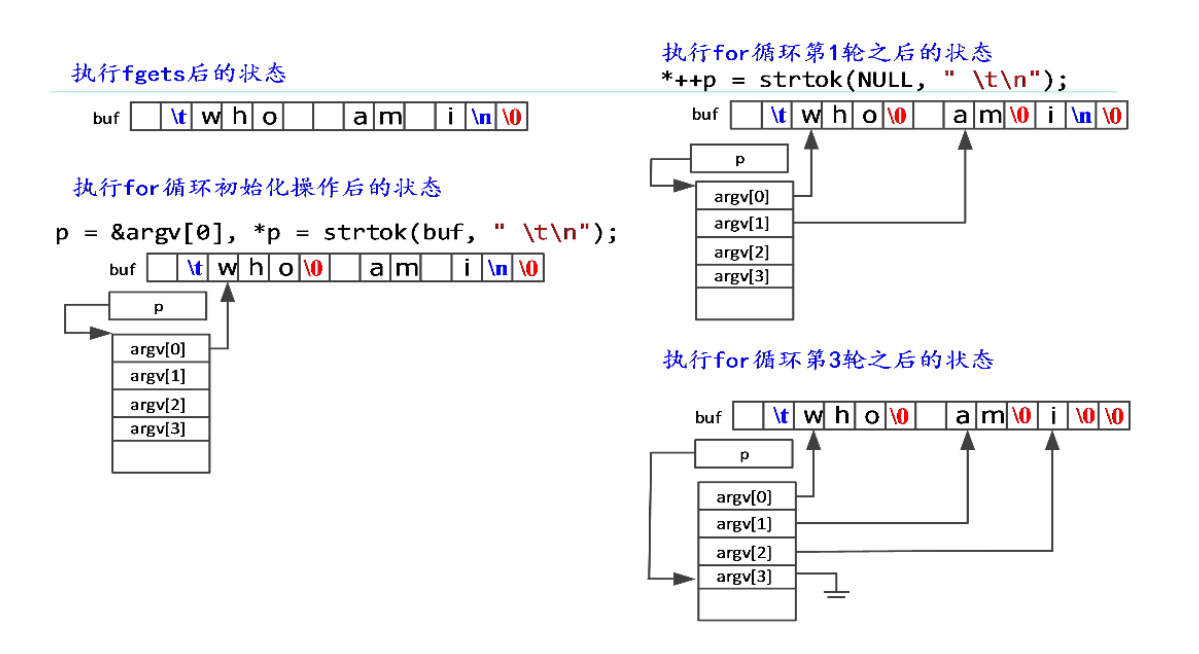
- exit是唯一的一个内部命令
- execvp(argv[0], argv)将子进程重新初始化为argv[0]指定的新程序,所以只有新程序执行失败才会输出”Bad command“
库函数system:运行一个命令
int system(char *string); - 执行用字符串传递的shell命令,可使用管道符和重定向
- 库函数system()是利用系统调用fork,exec,wait实现的
例:system("ls -l")会在程序运行时执行 UNIX/LINUX 的ls -l命令,列出当前目录中的文件和目录的详细列表。进程与文件描述符
活动文件目录AFD
磁盘文件目录(分两级)
磁盘文件目录是文件系统中用于组织和管理存储在磁盘上的文件和文件夹的结构。它提供了一种方式,让操作系统能够有效地定位、管理和维护磁盘上的文件。 - 文件名,i节点
i节点是 Unix 文件系统中的一种数据结构,用于存储文件或目录的元数据。每个文件或目录都有一个与之关联的 i节点,其中包含了如下信息:文件类型、权限、所有者、大小、时间戳、链接计数、数据块指针。活动文件目录(分三级)
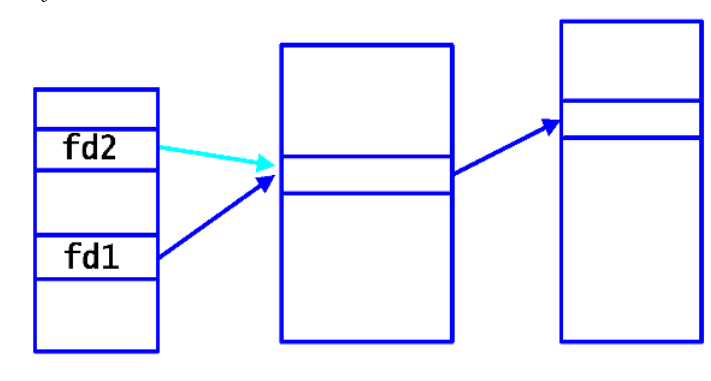
- 文件描述符表FDT:每进程一张,PCB的user结构中整型数组u_ofile记录进程打开的文件,文件描述符fd是u_ofile数组的下标。
- 系统文件表SFT:整个操作系统维护一张,用于存储所有打开文件的信息。对于每个打开的文件,存储如下信息:文件的当前偏移量(文件读写操作的当前位置)、文件打开模式、文件的引用计数、指向相关i节点的指针。
- 活动i节点表:整个操作系统维护一张,内存中inode表是外存中inode的缓冲,有个专用的引用计数
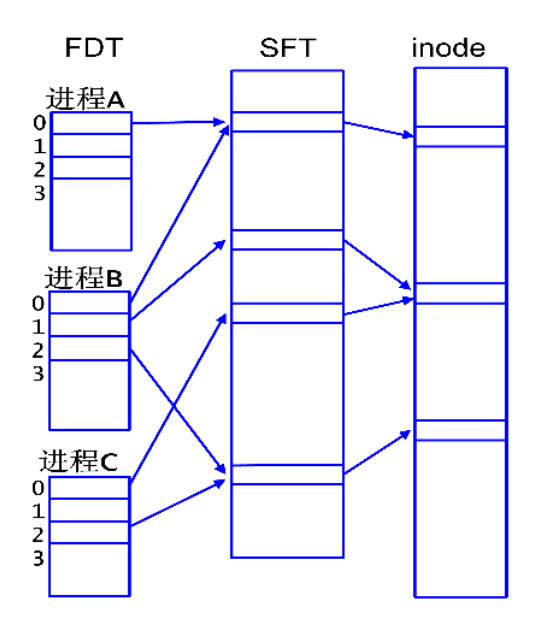
ps:图中存在一个细节问题:文件描述符0、1、2分别代表标准输入、标准输出、标准错误,不是普通的文件。文件描述符的继承与关闭
- fork创建的子进程继承父进程的文件描述符表
- 父进程在fork前打开的文件,父子进程有相同的文件偏移
close-on-exec标志

重定向
文件描述符的复制
系统调用 int dup2(int fd1, int fd2);
功能- 复制文件描述符fd1到fd2
- fd2可以是空闲的文件描述符,如果fd2是已打开文件,则关闭已打开文件
xsh1:输入输出重定向

管道与信号
管道
创建管道
int pipe(int pfd[2]);int pipe(int *pfd);int pipe(int pfd[]) - 创建一个管道,pfd[0]和pfd[1]分别为管道两端的文件描述字,pfd[0]用于读,pfd[1]用于写
管道写
ret = write(pfd[1],buf,n) - 若管道已满,则被阻塞,直到管道另一端read将已进入管道的数据取走为止
- 管道容量:某一有限值,如8192字节,与操作系统的实现相关
管道读
ret = read(pfd[0],buf,n) - 若管道写端已关闭,则返回0
- 若管道为空,且写端文件描述字未关闭,则被阻塞
- 若管道不为空(设管道中实际有m个字节)
n≥m,则读m个;
如果n<m则读取n个 - 实际读取的数目作为read的返回值。
- 注意:管道是无记录边界的字节流通信
关闭管道close
- 关闭写端则读端read调用返回0
- 关闭读端则写端write导致进程收到SIGPIPE信号(默认处理是终止进程,该信号可以被捕获)
进程间使用管道通信

写端
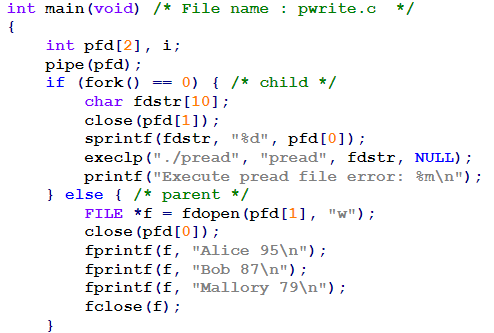
读端
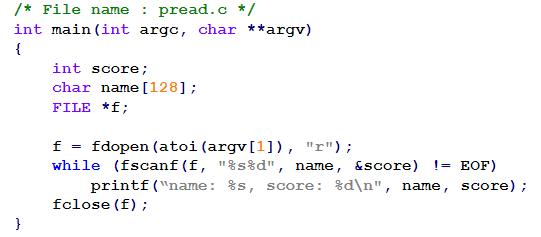
管道通信应注意的问题
管道传输是一个无记录边界的字节流 - 写端一次write所发数据读端可能需多次read才能读取
- 写端多次write所发数据读端可能一次read就全部读出
父子进程使用两个管道传递数据,有可能死锁
- 父进程因输出管道慢而写,导致被阻塞
- 子进程因要向父进程写回足够多的数据而导致写也被阻塞,产生死锁
命名管道
pipe创建的管道(匿名管道)的缺点:只限于同组先进程间通信
命名管道允许不相干的进程(没有共同的祖先)访问FIFO管道
用命令mknod pipe0 p创建管道,创建了一个文件pipe0,文件类型为p
发送者:fd = open("pipe0", O_WRONLY)write(fd, buf, len)
接收者:fd = open("pipe0", O_RDONLY)
信号
命令kill
kill -signal PID-list
kill命令用于向进程发送一个信号kill 1275
向进程1275的进程发送信号,默认信号为15(SIGTERM),一般会导致进程死亡kill -9 1326
向进程1326发送信号9(SIGKILL),导致进程死亡
进程组
- 进程在PCB结构中有p_pgrp域,p_pgrp相同的进程构成一个“进程组”,如果p_pgrp=p_pid则该进程是组长。
- setsid()系统调用将PCB中的p_pgrp改为进程自己的PID,从而脱离原进程组,成为新进程组的组长
- fork创建的进程继承父进程p_pgrp,与父进程同组
- kill命令的PID为0,向与本进程同组的所有进程发送信号
信号机制
信号是送到进程的“软件中断”,通知进程出现了非正常事件
信号的产生: - 用户态进程:自己或其它进程发出的
- 使用kill()或者alarm()调用
- 操作系统内核产生信号(往往由中断引发,也有软件触发)
- 设置为缺省处理方式(大部分处理是程序中止,有的会产生core文件)
signal(SIGINT, SIG_DFL)
- 信号被忽略
signal(SIGNT, SIG_IGN)- 执行了这个调用后,进程就不再收到SIGINT信号
- 信号被捕捉(用户事先注册好一个函数,当信号发生后就执行这一函数)
僵尸进程
- 子进程终止,僵尸进程(defunct或zombie)出现,父进程使用wait系统调用收尸后消除僵尸
- 僵尸进程不占用内存资源等但占用内核proc表项,僵尸进程太多会导致proc表耗尽而无法再创建新进程
- 子进程中止后,系统会向父进程发送信号SIGCLD
- 不导致僵尸子进程出现的方法:
- 当pid>0时,向指定的进程发信号
- 当pid=0时,向与本进程同组的所有进程发信号
- 当pid<0时,向以-pid为组长的所有进程发信号
- 当sig=0时,则信号根本就没有发送,但可据此判断一个已知PID的进程是否仍然运行
- 系统调用执行时会导致进程处于睡眠状态,如scanf、sleep等
- 进程正在睡眠时收到信号,进程就会从睡眠中被惊醒,系统调用被半途废止,返回值-1,errno一般被置为EINTR
pause与alarm系统调用
pause()
等待信号,进程收到信号前一直处于睡眠状态int alarm(int secs)
进程报警时钟存贮在它内核系统数据中,报警时钟到时,进程收到SIGALRM信号。 - 子进程继承父进程的报警时钟值。报警时钟在exec执行后保持这一设置
- 进程收到SIGALRM后的默认处理是终止进程
- 当secs>0时,将时钟设置成secs指定的秒数;当secs=0时,关闭报警时钟。
全局跳转


上述程序中存在的问题: - 每次按下中断键,程序停留在信号捕捉函数中,堆栈没有清理,嵌套越来越深浪费越来越大
- main_control()一旦返回,进程的执行将弹回到刚才被SIGINT中断的地方恢复刚才的执行
解决方法:栈恢复为进程某一留存的状态,程序执行也跳转到此int sigsetjmp(jmp_buf jmpenv, int savemask);void siglongjmp(jmp_buf jmpenv, int val)
进程间协作
信号灯
UNIX的IPC(Inter-Process Co)三样:信号灯(SEM)、共享内存(SHM)、消息队列(MSG)
信号灯(semaphore) - 控制多进程对共享资源的互斥性访问和进程间同步
- UNIX仅提供信号灯机制,访问共享资源的进程自身必须正确使用才能保证正确的互斥和同步,不正确的使用会导致信息访问不安全和死锁
- 信号灯机制实现了P操作和V操作,而且比简单PV操作功能更强
int semget(int key, int nsems, int glags) - 创建一个新的或获取一个已存在的信号灯组
- nsems:该信号灯组中包含有多少个信号灯
- 函数返回一个整数,信号灯组的ID号,如果返回-1,表明调用失败
- flags:创建或者获取
int semctl(int sem_id, int snum, int cmd, cahr *arg) - 对信号灯的控制操作,如:删除,查询状态
- snum:信号灯在信号灯组中的编号
- cmd:控制命令
- arg:执行这一控制命令所需要的参数存放区
- 返回值为-1,标志操作失败,否则表示执行成功
int semop(int sem_id, struct sembuf *ops, int nops) - 信号灯操作(可能会导致调用进程在此睡眠)
- ops:有nops个元素的sembuf结构体数组,每个元素描述对某一信号灯操作
- 返回值:-1,标志操作失败,否则表示执行成功当sem_op<0时,P操作;当sem_op>0时,V操作
1
2
3
4
5struct sembuf {
short sem_num;//信号灯在信号灯组中的编号
short sem_op; //信号灯操作,具有原子性
short sem_flag;//操作选项
};
当sem_op=0时,不修改信号灯的值,等待直到变为非负数共享内存
- 多个进程共同使用同一段物理内存空间
- 使用共享内存在多进程间传送数据,速度快,但进程必须自行解决对共享内存访问的互斥和同步问题
内存映射文件I/O
传统的访问磁盘文件的模式 - 打开一个文件,然后通过read和write访问文件
内存映射方式读写文件 - 将文件中的一部分连续的区域映射成一段进程虚拟地址空间中的内存
- 进程获取这段映射内存的指针后,就把这个指针当作普通的数据指针一样引用。修改其中的数据,实际修改了文件;引用其中的数据值,就是读取了文件
- 比使用read,write方式速度更快
- 提供了多个独立启动的进程共享内存的一种手段
内存映射文件相关系统调用


Socket编程
Socket
协议栈实现 - 传输层以上由用户态应用程序实现
- 传输层和网络互联层协议在内核中实现
- 第一第二层一般由硬件实现
Socket编程接口面向网络通信,不仅仅用于TCP/IPTCP与UDP
TCP - 面向连接
- 可靠
- 字节流传输
UDP
- 面向数据报
- 不可靠
- 丢报,乱序,流量控制
- 数据报传输
- 广播和组播
简单的TCP客户端/服务器程序
客户端程序


- 创建文件描述符socket
- 建立连接connect
- 进程阻塞,等待TCP连接建立
- 端点名的概念:IP地址+端口号
- 本地端点名
- 远端端点名
- 发送数据
- 发送速率大于通信速率,进程会被阻塞
- 关闭连接
服务端程序
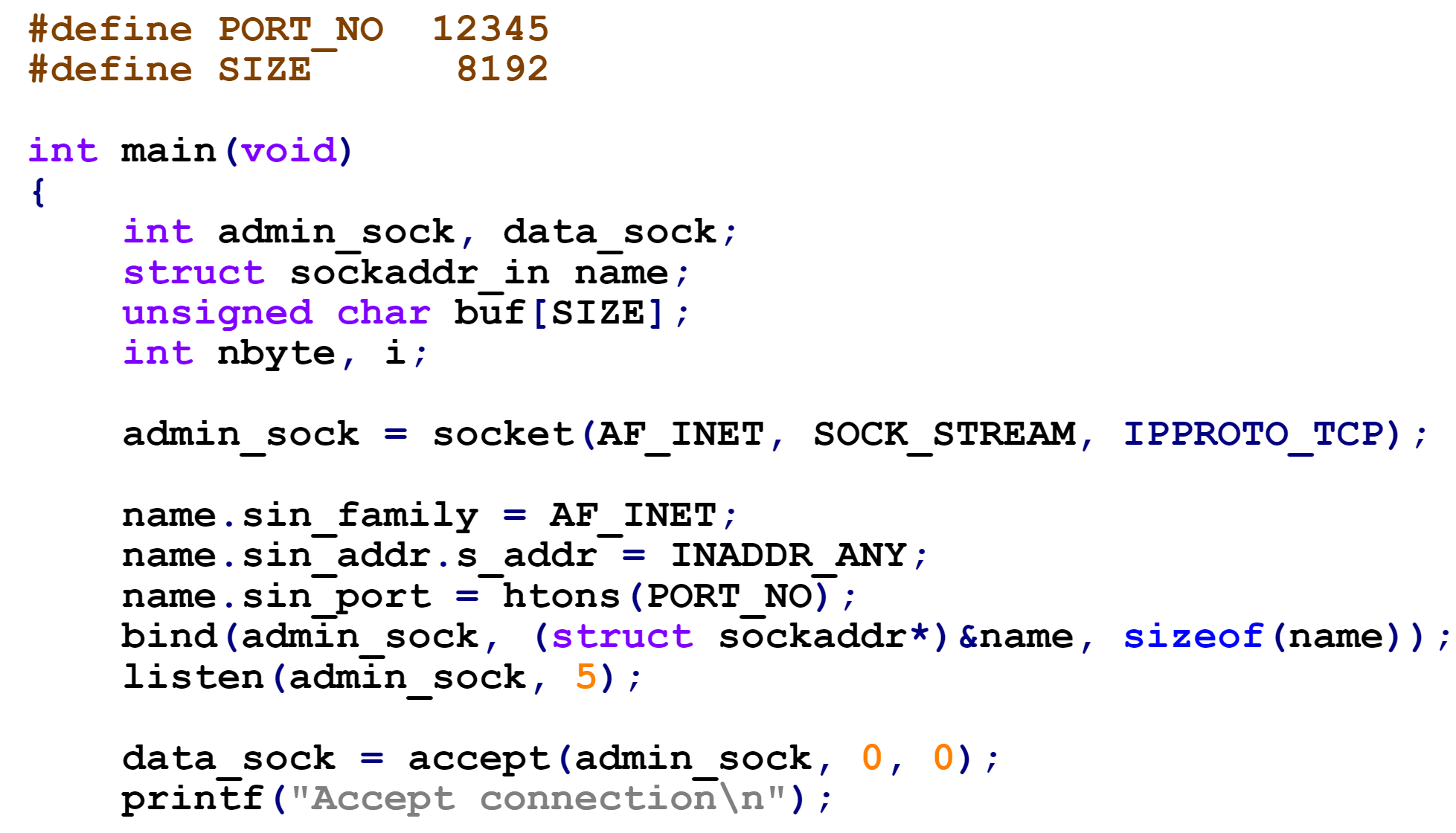

- bind
- 设定本地端点名
- 也可以用在客户端程序
- listen
- 进程不会在此被阻塞,仅仅给内核一个通知
- accept
- 进程会在这里阻塞等待新连接到来
- 创建新进程时的文件描述符处理
问题:不能同时接纳多个连接 - socket:创建文件描述符socket
- bind:设定本地端点名,也可以用在客户端程序
- listen:开始监听到达的连接请求
- accept:接受一个连接请求,TCP三次握手结束accept返回
- connect:建立连接,设定远端端点名,TCP连接建立,函数返回
- close:关闭连接,释放文件描述符
多进程并发处理
程序示例



端点名相关的系统调用
getpeername(int sockfd, struct sockaddr *name, int *namelen);获取对方的端点名getsockname(int sockfd, struct sockaddr *name, int *namelen);获取本地的端点名 - namelen是传入传出型参数,函数调用之前要先给整数namelen赋值,指出name缓冲区的可用字节数;函数返回时,namelen表示实际在name处写入了多少字节有效数据
read/write系统调用的语义
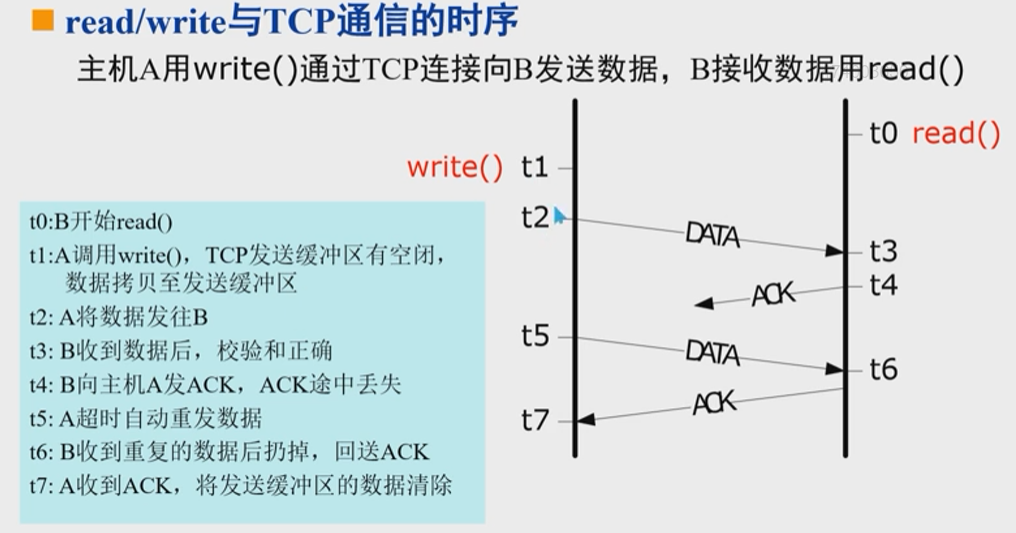
read/write与TCP通信故障和流控
- 流控问题
- 断线
- 对方重启动
- Keepalive(默认两小时)
- getsockopt/setsockopt可以设置保活间隔,重传次数,重传时间
read/write的其他版本

shutdown系统调用
int shutdown(int sockfd,int howto); - 禁止发送或接收。socket提供全双工通信,两个方向上都可以收发数据,shutdown提供了对于一个方向的通信控制
参数howto取值 - SHUT_RD:不能再接收数据,随后read均返回0
- SHUT_WR:不能再发送数据,对方read返回0;本方向再次write会导致SIGPIPE信号
- SHUT_RDWR:禁止这个sockfd上的任何收发
socket控制

单进程并发处理
select:多路I/O
引入select系统调用的原因 - 使得用户进程可同时等待多个事件发生
- 用户进程告知内核多个事件,某一个或多个事件发生时select返回,否则,进程睡眠等待

什么叫“准备好” - rfds中某文件描述符的read不会阻塞
- wfds中某文件描述符的write不会阻塞
- efds中某文件描述符发生了异常情况
- TCP协议,只有加急数据到达才算“异常情况”
- 对方连接关闭或网络故障,不算“异常情况”
“准备好”后可以进行的操作
- 当“读准备好”时,调用read会立刻返回-1/0/字节数
- 当“写准备好”时,调用write可以写多少字节?
- void FD_ZERO(fd_set *fds);
将fds清零:将集合fds设置为“空集” - void FD_SET(int fd, fd_set *fds);
向集合fds中加入一个元素fd - void FD_CLR(intfd, fd_set *fds);
从集合fds中删除一个元素fd int FD_ISSET(int fd,fd_set *fds);
判断元素fd是否在集合fds内select:时间
select的最后一个参数timeout
struct timeval{` long tv_sec;/*秒*/long tv_usec;/*微秒*/};定时值不为0:select在某一个描述符I/O就绪时立即返回;否则等待但不超过timeout规定的时限
- 尽管timeout可指定微秒级精度的时间段,依赖于硬件和软件的设定,实际实现一般是10毫秒级别
- 定时值为0:select立即返回(无阻塞方式查询)
- 空指针NULL:select等待到至少有一个文件描述符准备好后才返回,否则无限期地等下去
示例程序
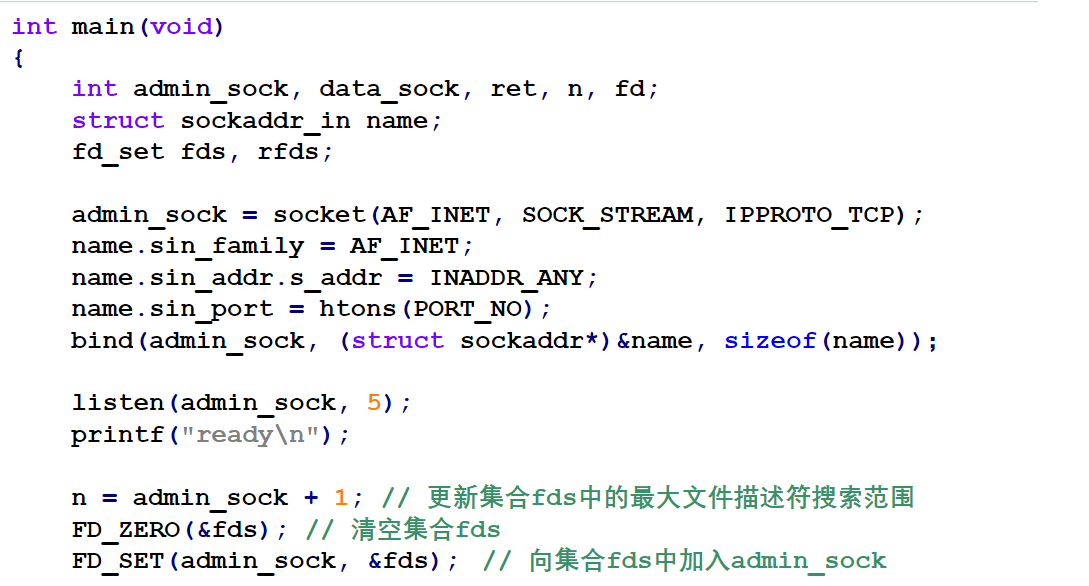

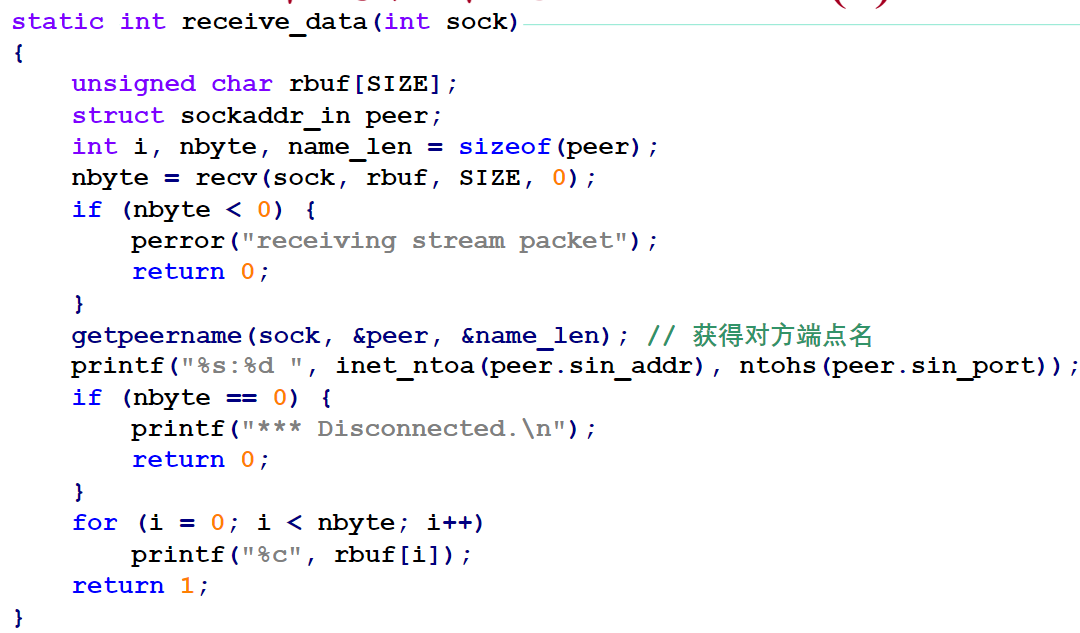
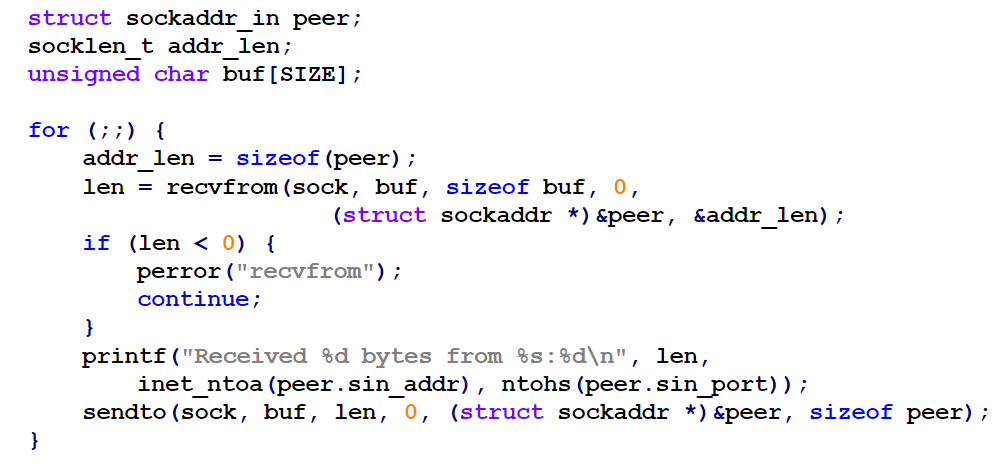
UDP通信
接收 - 没有数据到达时,read调用会使得进程睡眠等待
- 一般需区分数据来自何处,常用recvfrom获得对方的端点名
发送
- 服务器端发送数据常用sendto,指定远端端点名
- 对接收来的数据作应答,sendto引用的对方端点名利用recvfrom返回得到的端点名
select定时
- select可实现同时等待两个事件:收到数据和定时器超时
- 用time(0)或者gettimeofday()获得时间坐标,计算时间间隔决定是否执行超时后的动作
死锁问题客户端程序
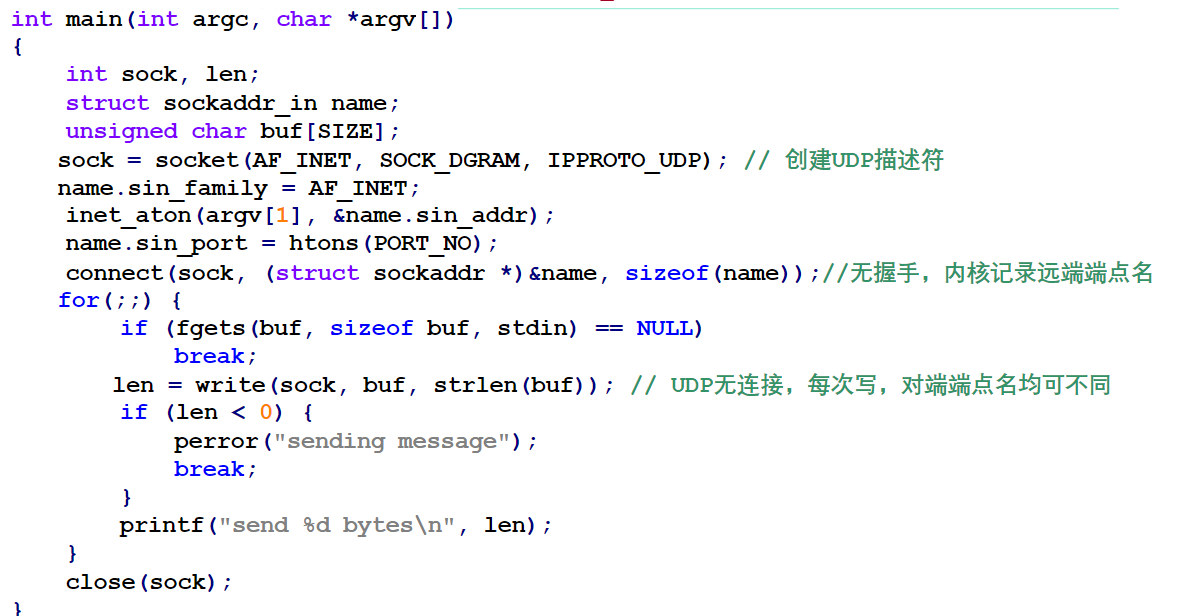
connect - 不产生网络流量,内核记下远端端点名
- 之前未用bind指定本地端点名,系统自动分配本地端点名
write